SIFT
图像检索原理概述
首先,我们要明白,图像检索,简单的说,便是从图片检索数据库中检索出满足条件的图片,图像检索技术的研究根据描述图像内容方式的不同可以分为两类:
一类是基于文本的图像检索技术,简称TBIR,
一类为基于内容的图像检索技术,简称CBIR。
两类图像检索技术
基于文本的图像检索(TBIR)技术,其主要原理为利用文本描述,如文本描述图片的内容、作者等等的方式来检索图片;
基于图像的内容语义的图像检索技术(CBIR),利用图片的颜色、纹理及图片包含的物体、类别等信息检索图片,如给定检索目标图片,在图像检索数据库中检索出与它相似的图片。
基于图像的内容语义的图像检索包括相同物体图像检索和相同类别图像检索,检索任务分别为检索同一个物体地不同图片和检索同一个类别地图片。例如,行人检索中检索的是同一个人即同一个身份在不同场景不同摄像头下拍得的图片属于相同物体的图像检索,而在3D形状检索中则是检索属于同一类的物品,如飞机等。
图像检索技术的步骤
图像检索技术主要包含几个步骤,分别为:输入图片、特征提取、度量学习、重排序。
特征提取:即将图片数据进行降维,提取数据的判别性信息,一般将一张图片降维为一个向量;
度量学习:一般利用度量函数,计算图片特征之间的距离,作为loss,训练特征提取网络,使得相似图片提取的特征相似,不同类的图片提取的特征差异性较大。
重排序:利用数据间的流形关系,对度量结果进行重新排序,从而得到更好的检索结果。
基于SFIT的图像特征提取
尺度不变特征转换即SIFT (Scale-invariant feature transform)是一种计算机视觉的算法。它用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量,此算法由 David Lowe在1999年所发表,2004年完善总结。
其应用范围包含物体辨识、机器人地图感知与导航、影像缝合、3D模型建立、手势辨识、影像追踪和动作比对。
局部影像特征的描述与侦测可以帮助辨识物体,SIFT特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、些微视角改变的容忍度也相当高。基于这些特性,它们是高度显著而且相对容易撷取,在母数庞大的特征数据库中,很容易辨识物体而且鲜有误认。使用 SIFT特征描述对于部分物体遮蔽的侦测率也相当高,甚至只需要3个以上的SIFT物体特征就足以计算出位置与方位。在现今的电脑硬件速度下和小型的特征数据库条件下,辨识速度可接近即时运算。SIFT特征的信息量大,适合在海量数据库中快速准确匹配。
SIFT算法的实质是在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出,不会因光照,仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
opencv中的SIFT算法
下面为一个简单算法样例
import cv2
import numpy as np
img = cv2.imread('home.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT()
kp = sift.detect(gray,None)
img=cv2.drawKeypoints(gray,kp)
cv2.imwrite('sift_keypoints.jpg',img)
函数 sift.detect() 可以在图像中找到关键点。如果只想在图像中的一个区域搜索的话,也可以创建一个掩模图像作为参数使用。返回的S关键点是一个
带有很多不同属性的特殊结构体,这些属性中包含它的坐标(x,y),有意义的
邻域大小,确定其方向的角度等。OpenCV 也提供了绘制关键点的函数:cv2.drawKeyPoints(),它可以在关键点的部位绘制一个小圆圈。如果设置参数为 cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,就会绘制代表关键点大小的圆圈甚至可以绘制除关键点的方向。
关于计算关键点描述符,OpenCV 提供了两种方法。
- 由于已经找到了关键点,可以使用函数
sift.compute()来计
算这些关键点的描述符。例如:kp, des = sif t.compute(gray, kp)。 - 如果还没有找到关键点,可以使用函数
sift.detectAndCompute()
一步到位直接找到关键点并计算出其描述符。
这里 kp 返回的是一个关键点列表。des是一个Numpy数组,其大小是关键点数目乘以 128。
代码框架
数据集
这里我选用了选用了101_ObjectCategories的图片作为本次模型训练数据。数据集下载地址:http://www.vision.caltech.edu/Image_Datasets/Caltech101/。
代码运行环境需要
- python 3.7 (Anaconda python)
- Numpy 1.16.2
- Matplotlib 3.1.1
- opencv-contrib-python 3.4.2.16
运行方法
把run模块中的image_path更改为对应的文件路径运行即可
算法流程图
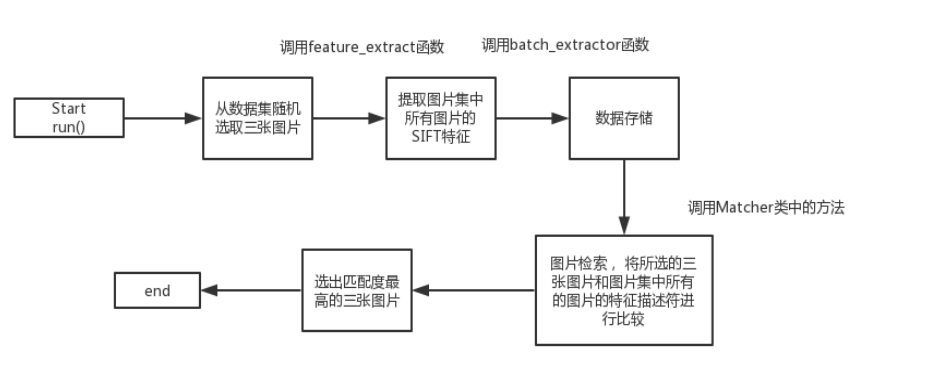
源代码
# Developer:Fazzie
# Time: 2020/6/1420:25
# File name: SIFT.py
# Development environment: Anaconda Python
import cv2
import numpy as np
import scipy
import _pickle as pickle
import random
import os
from matplotlib import pyplot as plt
import scipy.spatial
# 特征提取模块
def feature_extract(image_path,vector_size=32):
img = cv2.imread(image_path,1)#读取图片
# 显示图片
# cv2.imshow('image',img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# SIFT特征提取
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray, None)
# 画出特征点并保存
img = cv2.drawKeypoints(gray, kp, img)
cv2.imwrite('sift_keypoints.jpg', img)
# 根据关键点的返回值进行排序(越大越好)
kp = sorted(kp, key=lambda x: -x.response)[:vector_size]
# 计算描述符向量
kp, des = sift.compute(gray, kp)
# 将其放在一个大的向量中,作为我们的特征向量
des = des.flatten()
# 使描述符的大小一致
# 描述符向量的大小为128
needed_size = (vector_size * 128)
if des.size < needed_size:
# 如果少于32个描述符,则在特征向量后面补零
des = np.concatenate([des, np.zeros(needed_size - des.size)])
return des
# 数据存储
def batch_extractor(images_path, pickled_db_path="features.pck"):
files = [os.path.join(images_path, p) for p in sorted(os.listdir(images_path))]
result = {}
for f in files:
print('Extracting features from image %s' % f)
name = f.split('/')[-1].lower()
result[name] = feature_extract(f)
# 将特征向量存于pickled 文件
with open(pickled_db_path, 'wb') as fp:
pickle.dump(result, fp)
# 图像特征匹配模块
class Matcher(object):
def __init__(self, pickled_db_path="features.pck"):
with open(pickled_db_path,"rb") as fp:
self.data = pickle.load(fp)
self.names = []
self.matrix = []
for k, v in self.data.items():
self.names.append(k)
self.matrix.append(v)
self.matrix = np.array(self.matrix)
self.names = np.array(self.names)
def cos_cdist(self, vector):
# 计算待搜索图像与数据库图像的余弦距离
v = vector.reshape(1, -1)
return scipy.spatial.distance.cdist(self.matrix, v, 'cosine').reshape(-1)
def match(self, image_path, topn=5):
features = feature_extract(image_path)
img_distances = self.cos_cdist(features)
# 获得前5个记录
nearest_ids = np.argsort(img_distances)[:topn].tolist()
nearest_img_paths = self.names[nearest_ids].tolist()
return nearest_img_paths, img_distances[nearest_ids].tolist()
def show_img(path):
img = cv2.imread(path,1)
plt.imshow(img)
plt.show()
# 主程序
def run():
images_path = 'E:/Code/SFIT/101_ObjectCategories/panda/'
files = [os.path.join(images_path, p) for p in sorted(os.listdir(images_path))]
# 随机获取1张图
sample = random.sample(files, 1)
batch_extractor(images_path)
ma = Matcher('features.pck')
for s in sample:
print('Query image ==========================================')
show_img(s)
names, match = ma.match(s, topn=3)
print('Result images ========================================')
for i in range(3):
# 我们得到了余弦距离,向量之间的余弦距离越小表示它们越相似,因此我们从1中减去它以得到匹配值
print('Match %s' % (1 - match[i]))
show_img(os.path.join(images_path, names[i]))
run()
可能遇见的问题和解决方案
opencv库SFIT函数不可用(Error:cv2 has no attribute SIFT)
原因:在opencv3.4之后的版本SIFT,SURF等图像特征提取算法申请了专利,不包含在opencv的基本库里
解决方案:安装额外模块opencv contrib的,下载对应whl文件,在Anaconda对应目录的第三方包site-packages输入命令行:pip install 对应whl文件名
cpickle模块不可用
在python3中cpikle模块集成到了_pickle,import _pickle即可- 可以考虑使用SURF算法代替SIFT,进一步提高运算速率
如果想下载源码,可以访问https://github.com/Fazziekey/opencv_SIFT
