CNN“
卷积神经网络
Computer Version
传统的机器视觉的特征提取算法大都基于梯度实现,卷积神经网络为解决视觉问题提供了一个新的方法
边缘检测,特征提取
卷积运算是卷积神经网络的基本组成部分。下面以边缘检测的例子来介绍卷积运算。
所谓边缘检测,在下面的图中,分别通过垂直边缘检测和水平边缘检测得到不同的结果: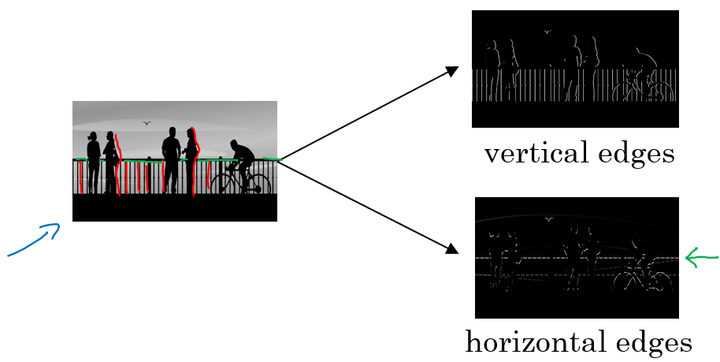
假设对于一个 $6\times6$ 大小的图片(以数字表示),以及一个 $3\times3$大小的 filter(卷积核) 进行卷积运算,以* 符号表示。图片和垂直边缘检测器分别如左和中矩阵所示: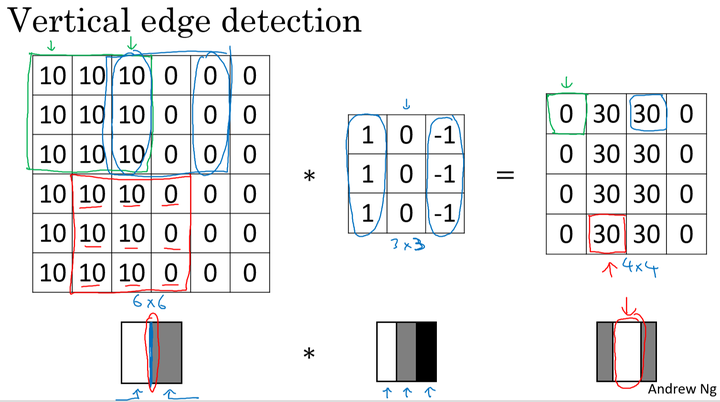
不同的边缘检测
水平和垂直

其他Filter
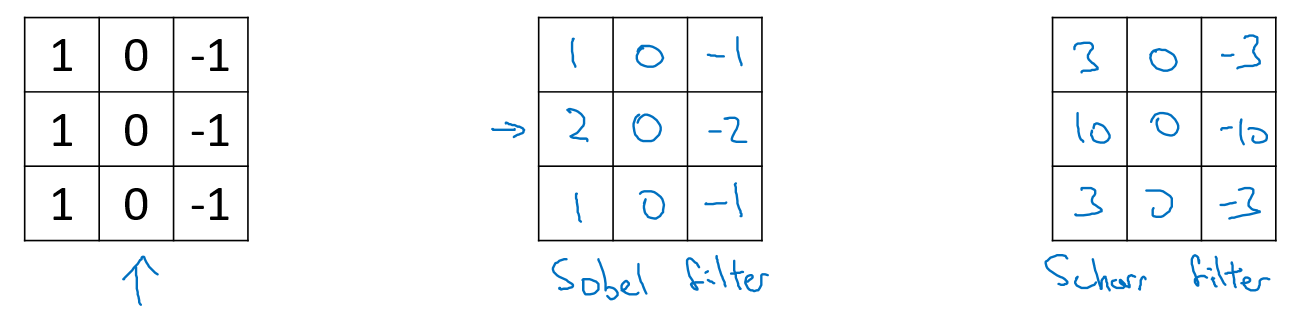
对于复杂的图片,我们可以直接将 filter 中的数字直接看作是需要学习的参数,其可以学习到对于图片检测相比上面filter更好的更复杂的 filter ,如相对于水平和垂直检测器,我们训练的 filter 参数也许可以知道不同角度的边缘。
通过卷积运算,在卷积神经网络中通过反向传播算法,可以学习到相应于目标结果的 filter,将其应用于整个图片,输出其提取到的所有有用的特征。
Padding
目的
在每次卷积运算中图片会缩小且边缘的特征信息损失
Stride卷积步长
卷积的步长是构建卷积神经网络的一个基本的操作。
如前面的例子中,我们使用的 stride=1,每次的卷积运算以1个步长进行移动。下面是 stride=2 时对图片进行卷积的结果: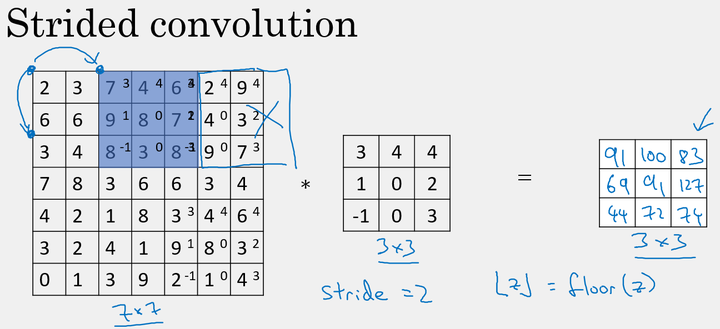
注意,在当 $padding =\not 1$ 时,若移动的窗口落在图片外面,则不要再进行相乘的操作,丢弃边缘的数值信息,所以输出图片的最终维度为向下取整。
三维卷积
对于有RGB三个通道的图像
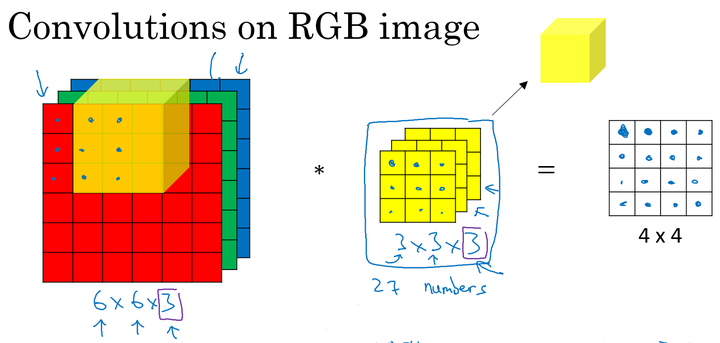
通过卷积得到二维的矩阵
多核卷积
单个卷积核应用于图片时,提取图片特定的特征,不同的卷积核提取不同的特征。如两个大小均为 $3\times3\times3$ 的卷积核分别提取图片的垂直边缘和水平边缘。
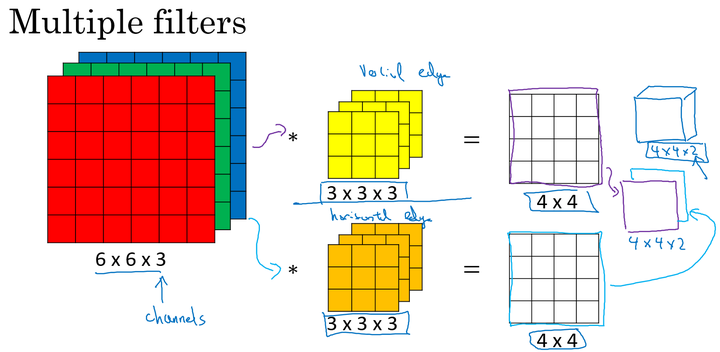
在卷积神经网络中,卷积核可以看做神经元,通过学习更新每个卷积核中的参数
卷积神经网络(CNN)
单层卷积神经网络
和普通的神经网络单层前向传播的过程类似,卷积神经网络也是一个先由输入和权重及偏置做线性运算,然后得到的结果输入一个激活函数中,得到最终的输出:
不同点是:在卷积神经网络中,权重和输入进行的是卷积运算。
网络参数(parameter)
10个$3\times3\times3$的卷积核+每个核的偏置
参数数量
标记总结
如果l表示一个卷积层
- $f^{[l]}$:filter的维度
- $p^{[l]}$:padding
- $s^{[l]}$:stride
- $n_C^{[l]}$:卷积核个数
- $f^{[l]}\times f^{[l]}\times n_c^{[l-1]}$:filter大小
- $a^{[l]} \to n_W^{[l]}\times n_H^{[l]}\times n_c^{[l]}$:Activation激活值
- $f^{[l]}\times f^{[l]}\times n_c^{[l-1]}\times n_c^{[l]}$:Weight权重
- $n_C^{[l]} —(1,1,1,n_C{[l]})$:bias
- $ n_W^{[l-1]}\times n_H^{[l-1]}\times n_C^{[l-1]}$:input
- $ n_W^{[l]}\times n_H^{[l]}\times n_C^{[l]}$:output
- 维度变化
卷积神经网络类型
- 卷积层(Convolution)
- 池化层(Pooling)
- 全连接层(Fully Connected)
Pooling
最大池化(Max pool)
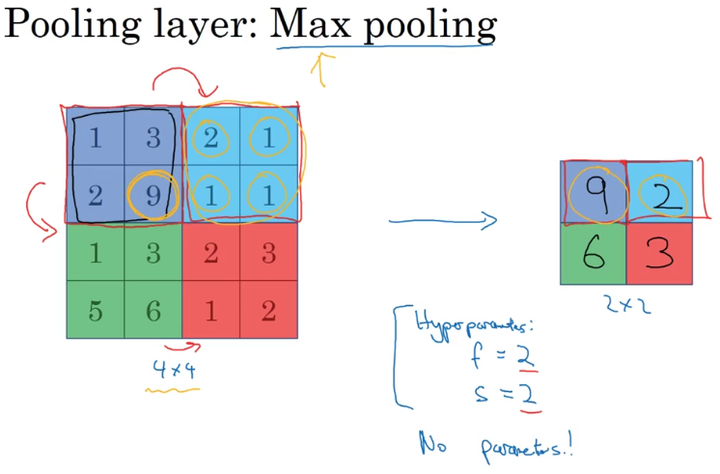
平均池化(Average Pooling)
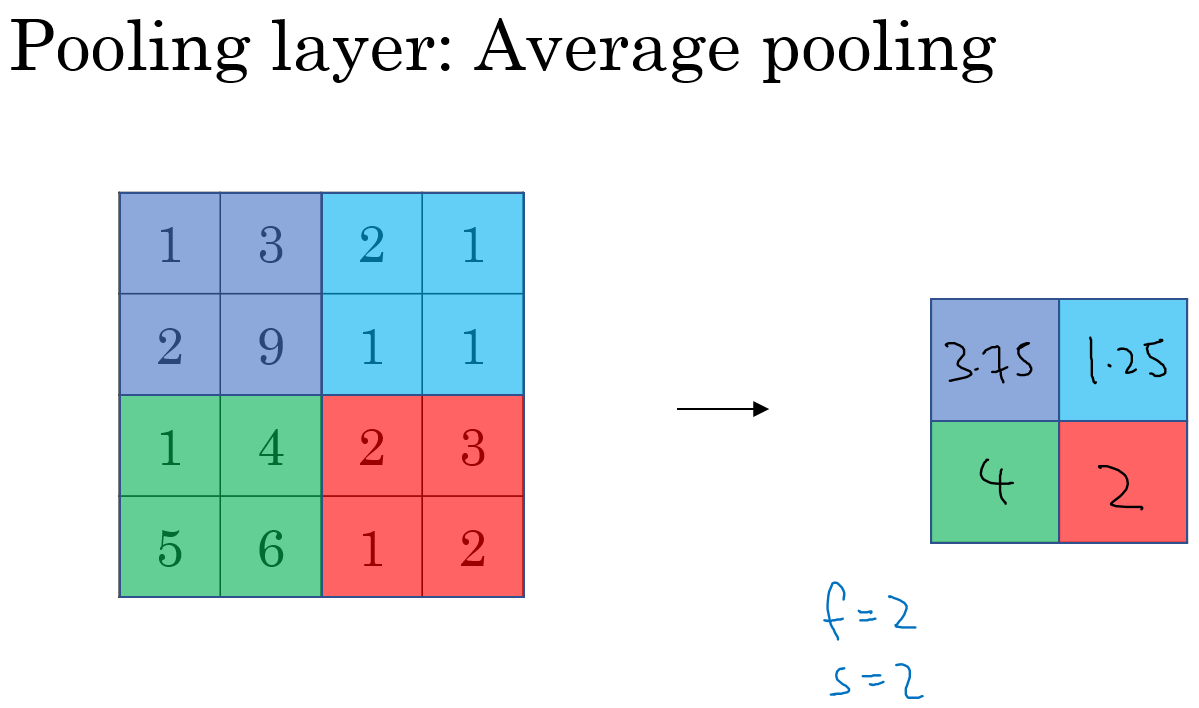
维度变化
参数
- f:filter的大小
- s:stride
- p:padding,很少使用
池化池没有要学习的参数,是对卷积层结果的压缩得到更加重要的特征,同时还能有效控制过拟合。
全连接层
作用
- 把二维特征图像转化为一维向量
- 分类
比如对于五个卷积核输出的$30\times 30 \times5$的特征图像,用一个$30\times 30 \times5\times 120$的卷积核去卷积,120为全连接层的神经元数量
卷积神经网络案例
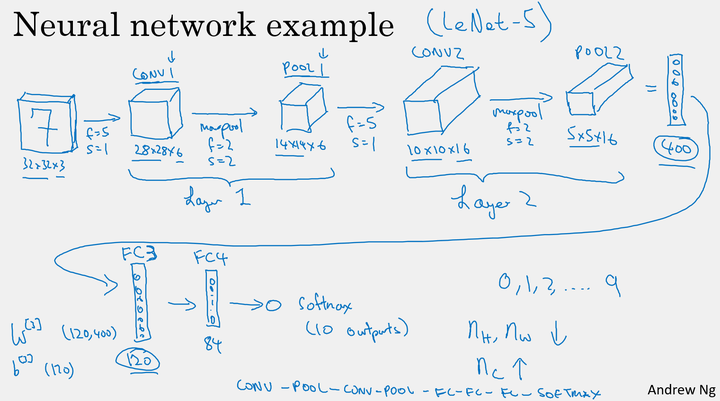
构建深度卷积的模式:
- 随着网络的深入,提取的特征图片大小将会逐渐减小,但同时通道数量应随之增加;
- Conv—Pool—Conv—Pool—Fc—Fc—Fc—softmax
参数
| layer | Activation shape | Activation size | pamameter | |
|---|---|---|---|---|
| Input | (32,32,3) | 3027 | 0 | |
| Conv1(f=5,s=1,n=8) | (28,28,8) | 6272 | 208 | |
| Pool1 | (14,14,8) | 1568 | 0 | |
| Conv2(f=5,s=1,n=8) | (10,10,16) | 1600 | 416 | |
| Pool2 | (5,5,16) | 400 | 0 | |
| FC1 | (120,1) | 120 | 48001 | |
| FC2 | (84,1) | 84 | 10081 | |
| Softmax | (10,1) | 10 | 841 |
- 在卷积层,仅有少量的参数;
- 在池化层,没有参数;
- 在全连接层,存在大量的参数。
常见卷积神经网络
LeNet-5
特点
针对灰度图像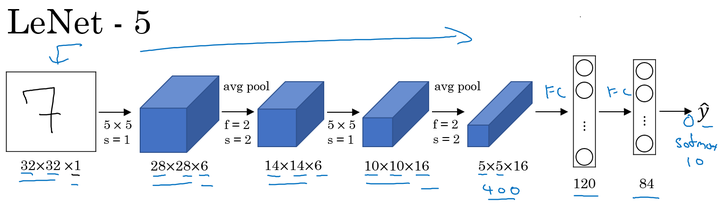
- 随着网络的深度增加,图像的大小在缩小,与此同时,通道的数量却在增加;
- 每个卷积层后面接一个池化层。
AlexNet
针对彩色图像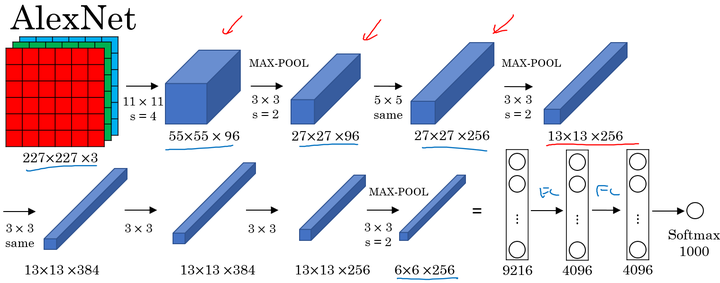
- 与LeNet相似,但网络结构更大,参数更多,表现更加出色;
- 使用了Relu;
- 使用了多个GPUs;
VGGNet
VGG卷积层和池化层均具有相同的卷积核大小,都使用 $3\times 3,stride=1,SAME$ 的卷积和$2\times2,stride=1$ 的池化。其结构如下: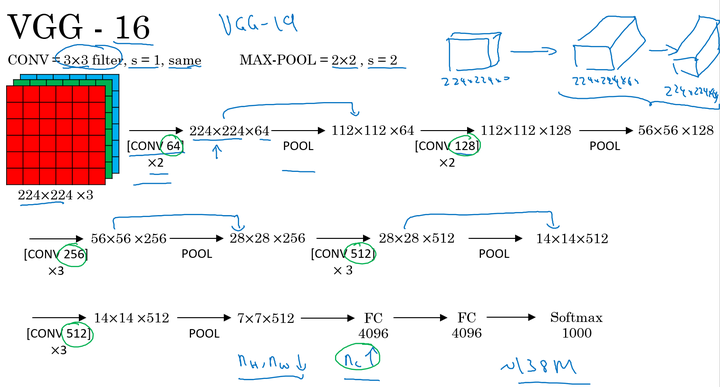
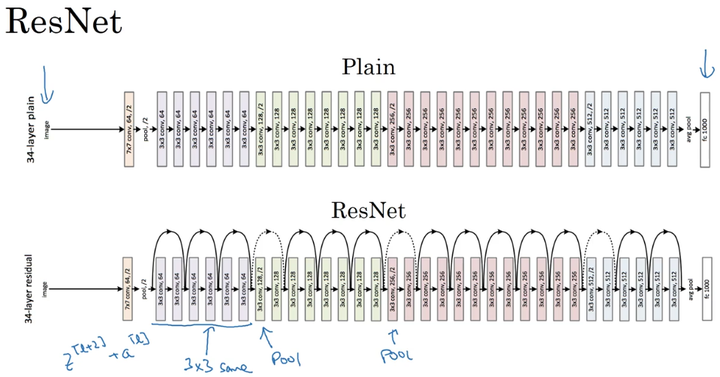
ResNet
残差快
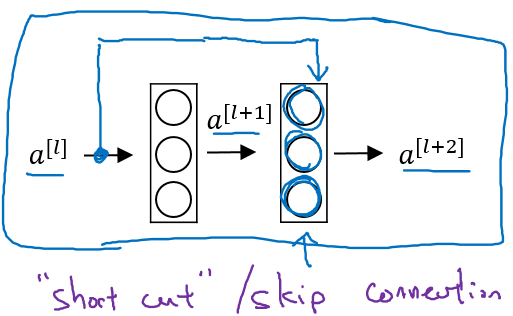
对于一个以下结构的网路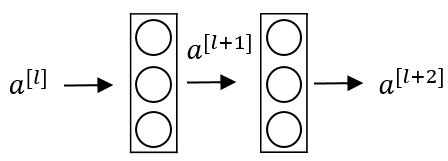
前向传播
而ResNet块则将其传播过程增加了一个从$a^{[l]}$直接到$a^{[l+2]}$ 的连接,将其称之为“short cut”或者“skip connection”
也就是
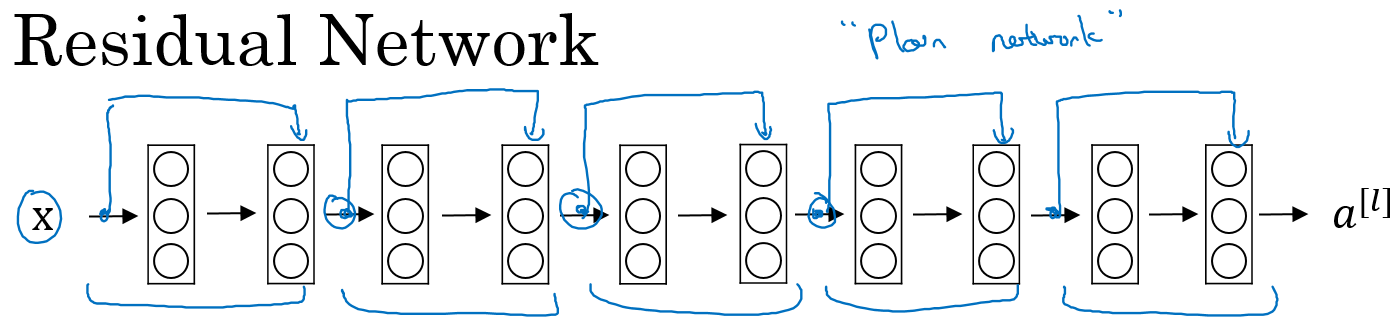
普通神经网络和ResNet的对比
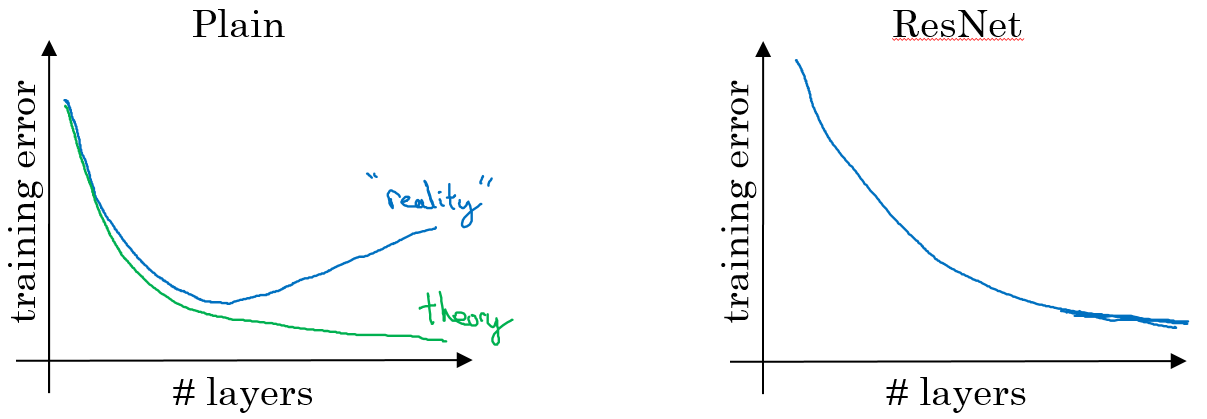
- 在没有残差的普通神经网络中,训练的误差实际上是随着网络层数的加深,先减小再增加;
- 在有残差的ResNet中,即使网络再深,训练误差都会随着网络层数的加深逐渐减小。
- ResNet对于中间的激活函数来说,有助于能够达到更深的网络,解决梯度消失和梯度爆炸的问题。
为什么ResNet性能更好?
初始化时$W^{[l+2]}=0,b^{[l+2]}=0$
则
在这里W和b可以看做开关,在不用的时候为0,这样更深结构的网络不会影响网络的性能
将普通神经网络转化为ResNet
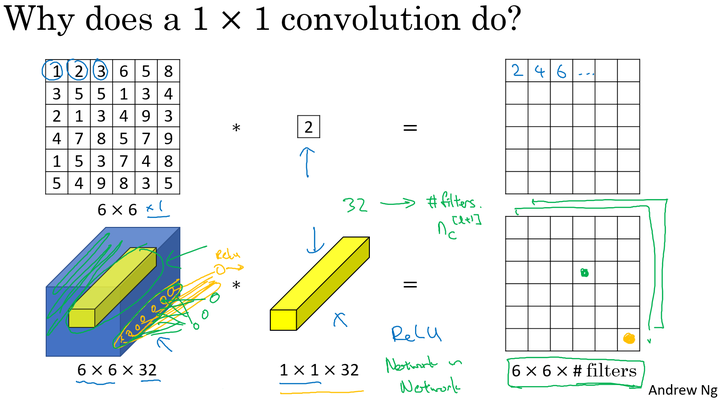
1$\times$1卷积
作用
- 维度压缩:使用目标维度的 的卷积核个数。
- 增加非线性:保持与原维度相同的 的卷积核个数。
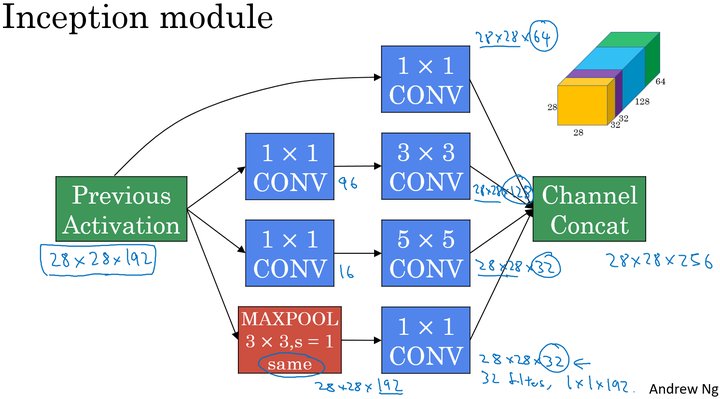
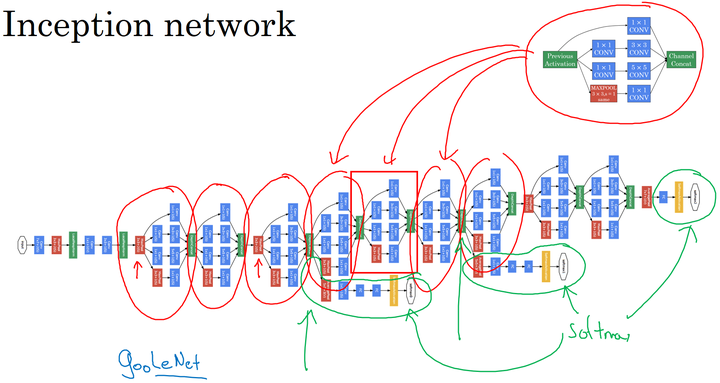
inception Network
网络结构
通过padding保证维度相同
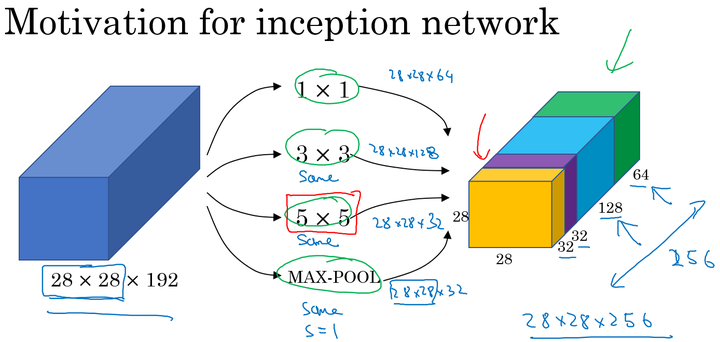
在上面的Inception结构中,应用了不同的卷积核,以及带padding的池化层。在保持输入图片大小不变的情况下,通过不同运算结果的叠加,增加了通道的数量。
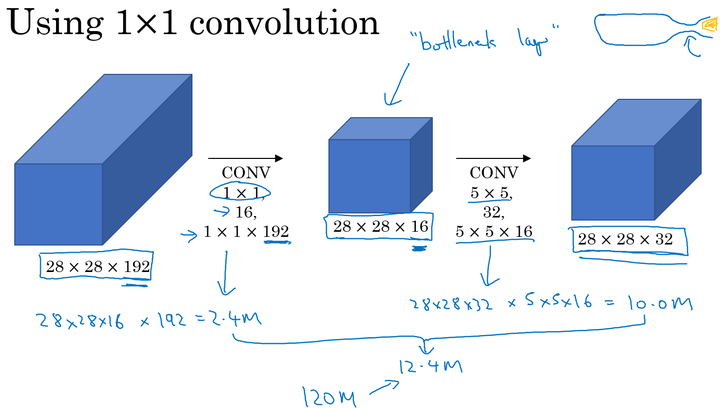
使用0ne by one降低计算成本
总计算成本
迁移学习
如今在深度学习领域,许多研究者都会将他们的工作共享到网络上。在我们实施自己的工作的时候,比如说做某种物体的识别分类,但是只有少量的数据集,对于从头开始训练一个深度网络结构是远远不够的。
但是我们可以应用迁移学习,应用其他研究者建立的模型和参数,用少量的数据仅训练最后自定义的softmax网络。从而能够在小数据集上达到很好的效果。
数据扩充
- 镜像翻转(Mirroring);
- 随机剪裁(Random Cropping);
- 色彩转换(Color shifting):
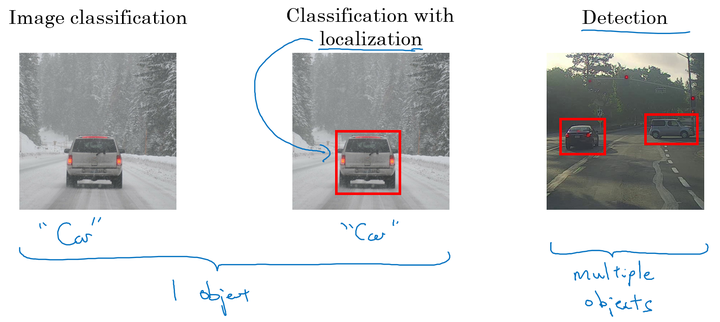
目标检测
- 分类问题:判断图中是否为汽车;
- 目标定位:判断是否为汽车,并确定具体位置;
- 目标检测:检测不同物体并定位。
网络结构
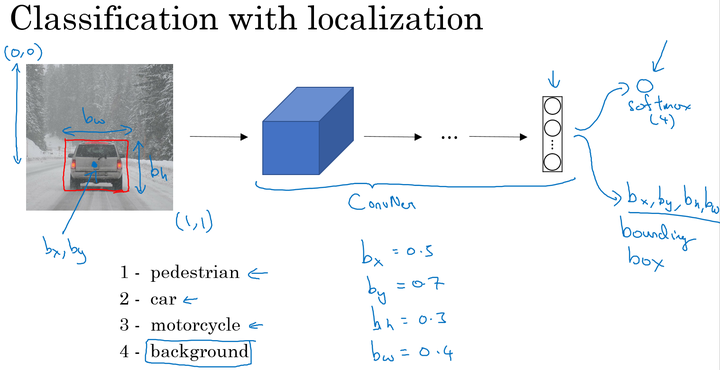
输出:包含图片中存在的对象及定位框
- 行人,0 or 1;
- 汽车,0 or 1;
- 摩托车,0 or 1;
- 图片背景,0 or 1;
- 定位框:$b_x,b_y,b_h,b_w$
其中,$b_x,b_y$表示汽车中点, $b_h,b_w$分别表示定位框的高和宽。以图片左上角为(0,0),以右下角为(1,1),这些数字均为位置或长度所在图片的比例大小。
Softmax层的输出
Loss Function
在实际的目标定位应用中,我们可以使用更好的方式是:
- softmax使用对数似然损失函数;
- 对边界框的四个值应用平方误差或者类似的方法;
- 对P_c应用logistic regression损失函数,或者平方预测误差。
特征检测
输出图片特征点来进行定位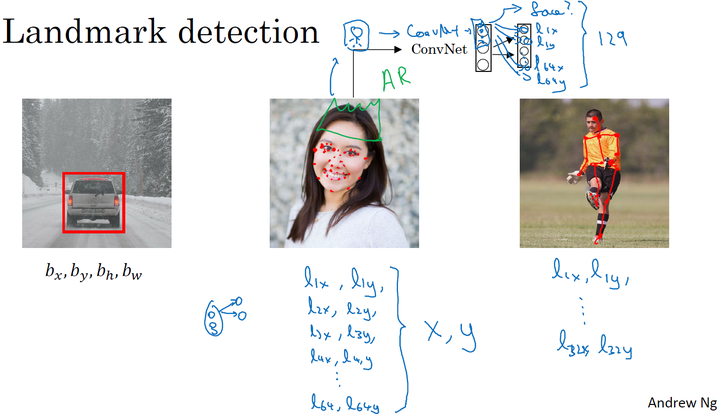
目标检测
目标框滑动检测

- 首先选定一个特定大小的窗口,将窗口内的图片输入到模型中进行预测;
- 以固定步幅滑动该窗口,遍历图像的每个区域,对窗内的各个小图不断输入模型进行预测;
- 继续选取一个更大的窗口,再次遍历图像的每个区域,对区域内是否有车进行预测;
- 遍历整个图像,可以保证在每个位置都能检测到是否有车。
缺点:计算成本巨大,每个窗口的小图都要进行卷积运算,(但在神经网络兴起之前,使用的是线性分类器,所以滑动窗口算法的计算成本较低)。
如何解决?
将全连接层转化为卷积层
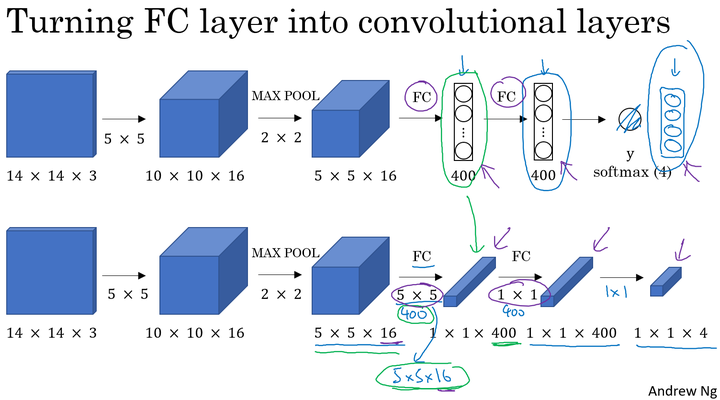
滑动窗口的卷积实现
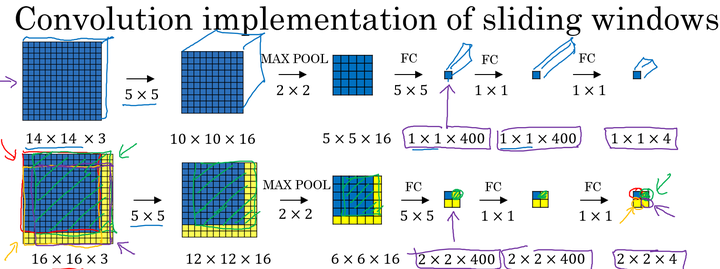
我们以上面训练好的模型,输入一个 $16\times16\times3$大小的整幅图片,图中蓝色部分代表滑动窗口的大小。我们以2为大小的步幅滑动窗口,分别与卷积核进行卷积运算,最后得到4幅$10\times10\times16$大小的特征图,然而因为在滑动窗口的操作时,输入部分有大量的重叠,也就是有很多重复的运算,导致在下一层中的特征图值也存在大量的重叠,所以最后得到的第二层激活值(特征图)构成一副$12\times12\times16$大小的特征图。对于后面的池化层和全连接层也是同样的过程。
那么由此可知,滑动窗口在整幅图片上进行滑动卷积的操作过程,就等同于在该图片上直接进行卷积运算的过程。所以卷积层实现滑动窗口的这个过程,我们不需要把输入图片分割成四个子集分别执行前向传播,而是把他们作为一张图片输入到卷积神经网络中进行计算,其中的重叠部分(公共区域)可以共享大量的计算。
利用卷积的方式实现滑动窗口算法的方法,提高了整体的计算效率。
Bounding Box
作用
解决非正方形的边框

YOLO
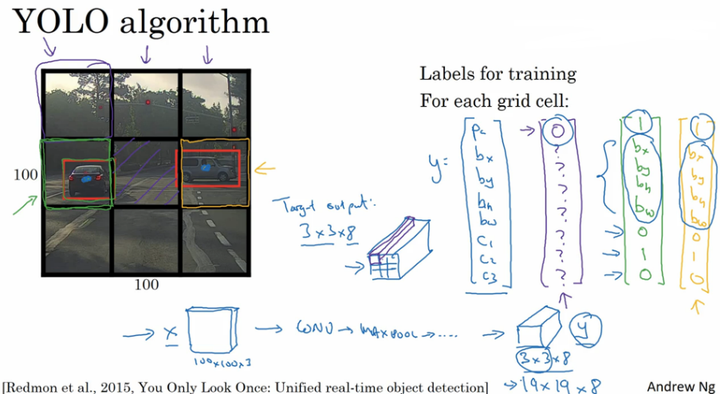
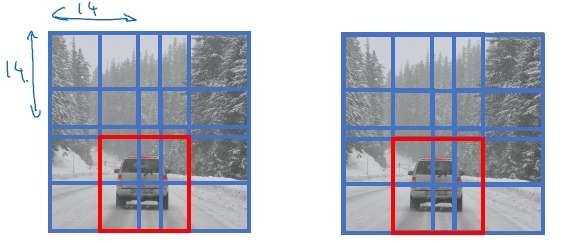
- 在整幅图片上加上较为精细的网格,将图片分割成$n\times n$个小的图片;
- 采用图像分类和定位算法,分别应用在图像的$n\times n$个格子中。
- 定义训练标签:(对于每个网格,定义如前面的向量$y_i$)
- 将 $n\times n$ 个格子标签合并在一起,最终的目标输出Y的大小为:$n\times n \times 8$ (这里8是因为例子中的目标值有8个)。
通过这样的训练集训练得到目标探测的卷积网络模型。我们利用训练好的模型,将与模型输入相同大小的图片输入到训练好的网络中,得到大小为 $n\times n\times8$的预测输出。通过观察 $n\times n$不同位置的输出值,我们就能知道这些位置中是否存在目标物体,然后也能由存在物体的输出向量得到目标物体的更加精准的边界框。
YOLO notation:
- 将对象分配到一个格子的过程是:观察对象的中点,将该对象分配到其中点所在的格子中,(即使对象横跨多个格子,也只分配到中点所在的格子中,其他格子记为无该对象,即标记为“0”);
- YOLO显式地输出边界框,使得其可以具有任意宽高比,并且能输出更精确的坐标,不受滑动窗口算法滑动步幅大小的限制;
- YOLO是一次卷积实现,并不是在 $n\times n$网格上进行$n^2$ 次运算,而是单次卷积实现,算法实现效率高,运行速度快,可以实现实时识别。
bounding boxes 细节:
利用YOLO算法实现目标探测的时候,对于存在目标对象的网格中,定义训练标签Y的时候,边界框的指定参数的不同对其预测精度有很大的影响。
- 对于每个网格,以左上角为(0,0),以右下角为(1,1);
- 中点$b_x,b_y$表示坐标值,在0~1之间;
- 宽高$b_h,b_w$表示比例值,存在>1的情况。
交并比IoU
交并比函数用来评价目标检测算法是否运作良好。
红框是人为标注的,紫框是训练结果
对于理想边界框和目标探测算法预测得到的边界框,交并比函数计算两个边界框交集和并集之比。
非最大值抑制(non-max suppression ,NMS)
作用:保证对一个对象不做多次检测

在上图中可能会有多个格子内检测出对象
NMS的基本思想
- 在对$n\times n$个网格进行目标检测算法后,每个网格输出的 [公式] 为一个0~1的值,表示有车的概率大小。其中会有多个网格内存在高概率;
- 得到对同一个对象的多次检测,也就是在一个对象上有多个具有重叠的不同的边界框;
- 非最大值抑制对多种检测结果进行清理:选取最大$P_c$ 的边界框,对所有其他与该边界框具有高交并比或高重叠的边界框进行抑制;
- 逐一审视剩下的边界框,寻找最高的$P_c$值边界框,重复上面的步骤。
- 非最大值抑制,也就是说抑制那些不是最大值,却比较接近最大值的边界框。
以单对象检测为例
- 对于图片每个网格预测输出矩阵: $y=[P_c,b_x,b_y,b_h,b_w]$,其中 $P_c$表示有对象的概率;
- 抛弃$P_c<=0.6$的边界框,也就是低概率的情况;
- 对剩余的边界框(while):
- 选取最大$P_c$ 值的边界框,作为预测输出边界框;
- 抛弃和选取的边界框$IoU>=0.5$ 的剩余的边界框。
对于多对象检测,输出标签中就会有多个分量。正确的做法是:对每个输出类别分别独立进行一次非最大值抑制。
Anchor Box
作用:解决两个目标出现在一个框内的情况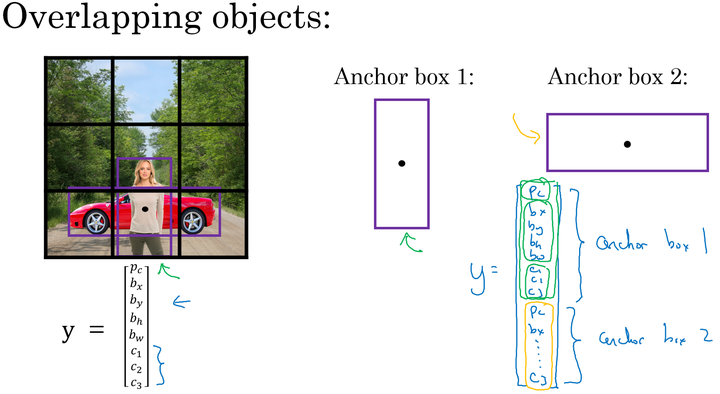
先定义几个Anchor Box,目标向量变为
不使用Anchor box:训练图片中的每个对象,根据对象的中点,分配到对应的格子中。输出大小
- 使用Anchor box:训练图片的每个对象,根据对象的中点,分配到对应的格子中,同时还分配到一个和对象形状的IoU最高的Anchor box 中。输出大小(例如两个Anchor box)$n\times n \times 16$。
难点问题:
- 如果我们使用了两个Anchor box,但是同一个格子中却有三个对象的情况,此时只能用一些额外的手段来处理;
- 同一个格子中存在两个对象,但它们的Anchor box 形状相同,此时也需要引入一些专门处理该情况的手段。
Anchor box 的选择:
- 一般人工指定Anchor box 的形状,选择5~10个以覆盖到多种不同的形状,可以涵盖我们想要检测的对象的形状;
- 高级方法:K-means 算法:将不同对象形状进行聚类,用聚类后的结果来选择一组最具代表性的Anchor box,以此来代表我们想要检测对象的形状。
YOLO算法
基本流程
- 构造数据集
- 模型训练
- 运行NMS
案例
假设我们要在图片中检测三种目标:行人、汽车和摩托车,同时使用两种不同的Anchor box。
训练集
- 输入X:同样大小的完整图片;
- 目标Y:使用$3\times 3$ 网格划分,输出大小$3\times 3\times2\times8$,或者$3\times 3\times16$
- 对不同格子中的小图,定义目标输出向量Y。
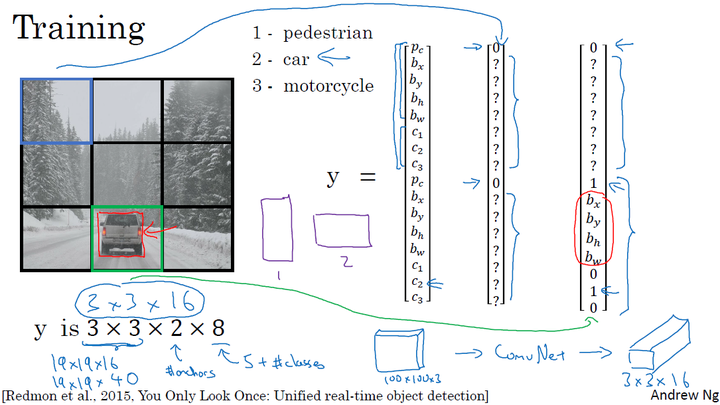
模型训练
输入与训练集中相同大小的图片,同时得到每个格子中不同的输出结果: $3\times 3\times2\times8$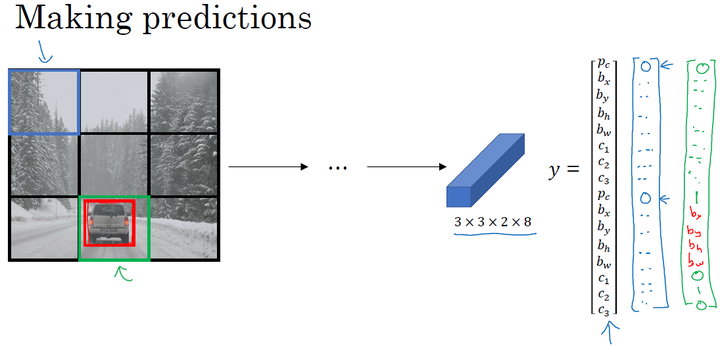
运行NMS
- 假设使用了2个Anchor box,那么对于每一个网格,我们都会得到预测输出的2个bounding boxes,其中一个Pc比较高;

抛弃概率Pc值低的预测bounding boxes;

对每个对象(如行人、汽车、摩托车)分别使用NMS算法得到最终的预测边界框

候选区域
- R-CNN(Regions with convolutional networks),会在我们的图片中选出一些目标的候选区域,从而避免了传统滑动窗口在大量无对象区域的无用运算。
- 所以在使用了R-CNN后,我们不会再针对每个滑动窗口运算检测算法,而是只选择一些候选区域的窗口,在少数的窗口上运行卷积网络。
- 具体实现:运用图像分割算法,将图片分割成许多不同颜色的色块,然后在这些色块上放置窗口,将窗口中的内容输入网络,从而减小需要处理的窗口数量。

更快的算法:
- R-CNN:给出候选区域,不使用滑动窗口,对每个候选区域进行分类识别,输出对象 标签 和 bounding box,从而在确实存在对象的区域得到更精确的边界框,但速度慢;
- Fast R-CNN:给出候选区域,使用滑动窗口的卷积实现去分类所有的候选区域,但得到候选区的聚类步骤仍然非常慢;
- Faster R-CNN:使用卷积网络给出候选区域。
CNN的其他应用
人脸识别和人脸验证
Verification
- input image,nameID
- Output true or flase
Recognition
- K person in database
- input a image
- out put the id or name of the person
One-shot学习
人脸识别的困难点在于一次学习识别,训练样例只有一个
为什么不用softmax?
softmax的缺点在于加入新人后需要重新训练网络
degree of difference between two picture
引入Similarity函数
siamese网络
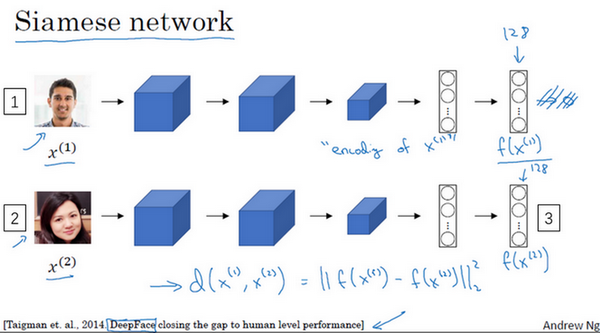
如何训练?
定义编码函数$f(x^i)$,输入$x^i$,得到对应编码
Triplet 损失
Tripletloss between A N P
定义三个变量
- anchor
- positive正确的
- nagetive错误的存在问题
当A和N差别过大时梯度下降很小,网络并不能学到什么,所以在训练的时候要选取尽可能难区分的数据
人脸验证与二分类
用二分类的思想训练网络
- 输入两张图片
- 输出是否为同一个人
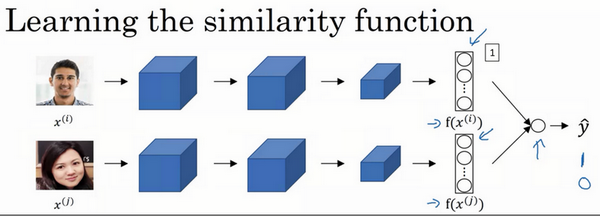
逻辑回归单元的处理
神经风格迁移

CNN特征可视化

- 找出让单元最大激活化的图片快

- 在越深的层会检测到越复杂的特征
神经风格迁移代价函数
cost function
content cost
利用一个训练好的卷积模型,如VGG
style cost
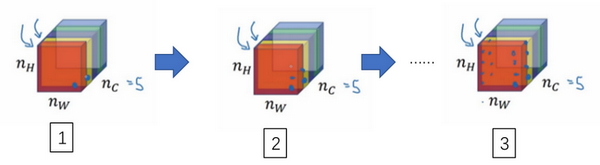
- 通道1检测出垂直纹理
- 通道2检测出橙色
现在利用相关系数描述同时出现两种特征的的概率
定义风格矩阵:style matrix
