论文解读:Lite Transformer
LITE TRANSFORMER WITH LONG-SHORT RANGE ATTENTION
本篇文章来袭MIT 韩松的团队,我们先看摘要
摘要
Transformer网络结构在自然语言处理中已经被广泛应用(如机器翻译,回答等);然而,它需要大量的计算资源来实现高性能,硬件资源和电池容量的限制使得它很难在端侧设备部署。在本文中,我们提出了一个高效的移动NLP架构—Lite Transformer,以便于在边缘设备上部署基于Transformer的NLP模型。其关键点是 Long Short range attention(长短程注意力,LSRA),它由两部分组成,一部分走传统的self-attention,这部分可以得到长距离的关系;另一部分使用一个精简版本的卷积神经网络,这部分来获得短距离的关系长距离关系建模(通过注意)。在三个通用NLP任务:机器翻译、抽象概括和语言建模上,Lite Transformer相比普通的transformer都有明细的性能提升。在资源受限的情况下(500M/100M MACs),Lite Transformer在数据集WMT’14的英语-法语翻译任务上的表现超过了Transformer,其BLEU分别为1.7和1.2 BLEU。Lite Transformer将transformer模型的计算量减少了2.5倍,而BLEU得分只下降了0.3。通过剪枝和量化,我们进一步将Lite Transformer的模型大小压缩了18.2倍。同时,Lite Transformer和基于AutoML的Evolved Transformer相比,BLEU得分高了0.5,却不需要花费大量的GPU资源进行参数搜索。
论文试图解决什么问题?
本篇文章的Lite Transformer模型对比了传统的Transformer模型和基于AutoML 的 Evolved Transformer,试图解决原有模型计算量大的的缺点。
- Transformer的优点
Transformer模型因其高训练效率和捕获长距离依赖关系的优越能力,在自然语言处理中得到广泛应用。在此基础上,现在NLP各任务上的SOTA模型,如BERT,能够从未标记的文本中学习语言表征,在具有挑战性的问题回答任务上甚至超过人类的表现。
- Transformer的缺点
Transformer良好的性能表现需要很高的计算代价。例如,一个单个的Transformer模型需要超过 10G 的 Mult-Adds 才 能翻译一个只有30个单词的句子。同样,利用AutoML搜索参数的Evolved Transformer也需要大量的搜索成本,消耗大量的GPU资源。
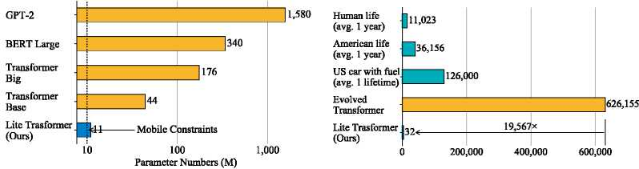
(模型参数和训练开销对比)
所以对于计算能力受限的边缘设备的能力,如智能手机 和 lot 设计高效快速的Transformer结构具有重要意义,本文提出的模型Lite Transformer也正是为了解决这个问题。
这是否是一个新的问题?
是,Transformer模型出现后,各种大规模预训练模型如GPT,Bert不断出现,预训练成为NLP任务的主流方式,对于算力受限的边缘设备,设计一个轻量化的Transformer模型尤为关键。
这篇文章要验证一个什么科学假设?
注意力机制引入了大量的计算量。假设元素的数量(例如,语言处理中的标记符的长度、图像中的像素数等)。输入注意层为N,特征(即通道)的维数为d,点积所需的计算量为$N^2d$.对于图像和视频,N通常非常大。例如,视频网络中的中间特征图有 16帧,每帧的分辨率为 $112 \times 112$,导致 $N = 2\times 10^5$。卷积层和全连通层的计算呈$w\cdot r\cdot t\cdot N$级别的线性增长,而注意层的计算呈$w\cdot r\cdot t\cdot N$的二次增长。
为了解决这一困境,通常的做法是首先在应用注意力层之前使用线性投影层减少通道数d,然后增加维数 (如图所示)。在Transformer的原始设计中,注意力模块的通道尺寸比FFN 层的小 4倍。但是它也降低了具有较小特征维度的注意层的上下文捕获能力。语言处理的情况可能更糟,因为注意力是上下文捕获的主要模块
作者通过研究Transformer的计算分布,发现计算量(Mult-Adds)由前馈网络(FFN)主导。普遍存在的BottleNeck层使Transformer块效率低下。如果能把FFN层用其他计算效率更高的层替换,那么计算效率一定可以提升,更少参数的网络也可以达到同样的效果。
简单来说,就是作者认为原有Transformer为了减少计算量的FFN层本身也消耗了大量计算时间,所以直接将其去掉,用一个不做维度变化的层代替。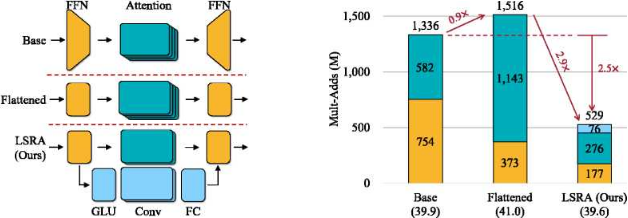
论文中提到的解决方案之关键是什么?
针对上述假设,作者提出了一种新的Long-Short Range Attention(长-短距离注意力,LSRA)的基本模块。LSRA 把 FFN 中的计算换成更广泛的注意力层。它延长了瓶颈,为注意层引入了更多的捕获依赖的能力,然后作者在保证性能不降低的情况下,缩小了Embedding层的大小,以减少了总的计算量。Lite Transformer基本的模块如下
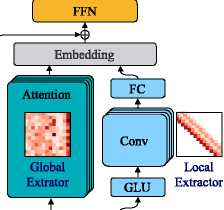
可以看到整个Lite Transformer分为两个模块,一个Attention层和一个卷积层,这个设计也就是本篇文章的核心思想所在,作者认为对于翻译任务,模型需要同时捕捉全局信息和本地局部信息,原Transformer模型用了8个注意力头,也就是Multi-Head Attention去捕捉全局和局部信息,作者认为这样的设计是冗余的,所以作者设计了两个模块分别捕捉全局和局部信息。
卷积注意力
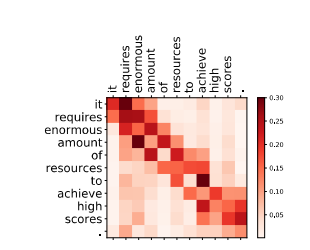
不少文章中认为卷积神经网络用于NLP任务效果不如Transformer的原因是CNN不擅长捕捉长远的信息,因为CNN本身是通过滑窗实现的,这样的计算方式本身就更适合提取本地信息。所以作者直接将其用于提取本地信息,将注意力值可视化后结果如下,可以看出每个词对邻近词的关注度更大。
Attention层
Lite Transformer的Attention层只有一个头,可视化后结果如下,可以看出Attention层的注意力分布不集中在邻近,更关注长远的注意力。
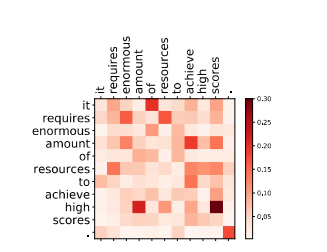
综上所述,作者用一个卷积层和注意力层分别捕捉全局和局部信息,这样专业化的设置可以用更浅的网络得到同样的信息。
论文中的实验是如何设计的?
作者在机器翻译、文本摘要和语言建模三个任务上进行了实验和评估。具体而言,机器翻译任务使用了三个基准数据集:IWSLT’14 德语 - 英语 (De-En)、WMT 英语 - 德语 (En-De)、WMT 英语 - 法语(En-Fr)。文本摘要任务使用的是 CNN-DailyMail 数据集。语言建模任务则在 WIKITEXT-103 数据集上进行。
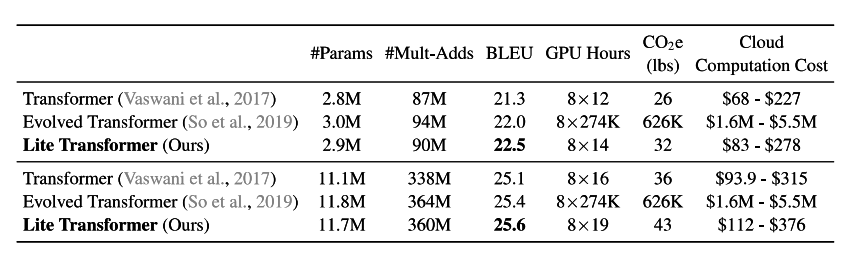
可以看出在参数量接近的情况下,LiteTransformer和效果个训练开销都更加优秀。
