pytorch basic
激励函数
常见激励函数
| 函数 | 作用场景 |
|---|---|
| relu | CNN |
| sigmoid | 二分类 |
| tanh | RNN |
| softmax | 多分类 |
| softplus |
导入函数包
import torch.nn.functional as F
神经网络搭建基本步骤
- 数据加载
- 网络搭建
- 优化器合损失函数定义
- 训练
网络搭建
class Net(torch.nn.Module): # 继承 torch 的 Module
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__() # 继承 __init__ 功能
# 定义每层用什么样的形式
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐藏层线性输出
self.predict = torch.nn.Linear(n_hidden, n_output) # 输出层线性输出
def forward(self, x): # 这同时也是 Module 中的 forward 功能
# 正向传播输入值, 神经网络分析出输出值
x = F.relu(self.hidden(x)) # 激励函数(隐藏层的线性值)
x = self.predict(x) # 输出值
return x
查看网络结构
print (net)
optimizer优化器选择和损失函数定义
optimizer = torch.optim.SGD(net.parameters(), lr=0.2) # 传入 net 的所有参数, 学习率
loss_func = torch.nn.MSELoss() # 预测值和真实值的误差计算公式 (均方差)
训练
for t in range(100):
prediction = net(x) # 喂给 net 训练数据 x, 输出预测值
loss = loss_func(prediction, y) # 计算两者的误差
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
optimizer.step() # 将参数更新值施加到 net 的 parameters 上
快速搭建
使用torch.nn.Sequential
保存提取
保存
torch.save(net1,'net.pkl')#保存整个网络
torch.save(net.state_dict(),'net_params.pkl') #保存参数
提取
提取网络
def restore_net():
# restore entire net1 to net2
net2 = torch.load('net.pkl')
prediction = net2(x)
只提取参数(速度快)
def restore_params():
# 新建 net3
net3 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
# 将保存的参数复制到 net3
net3.load_state_dict(torch.load('net_params.pkl'))
prediction = net3(x)
批训练
pytorch的dataloader模块提供的批训练的基本函数
import torch
import torch.utils.data as Data
torch.manual_seed(1) # reproducible
BATCH_SIZE = 5 # 批训练的数据个数
x = torch.linspace(1, 10, 10) # x data (torch tensor)
y = torch.linspace(10, 1, 10) # y data (torch tensor)
# 先转换成 torch 能识别的 Dataset
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 把 dataset 放入 DataLoader
loader = Data.DataLoader(
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
for epoch in range(3): # 训练所有!整套!数据 3 次
for step, (batch_x, batch_y) in enumerate(loader): # 每一步 loader 释放一小批数据用来学习
# 假设这里就是你训练的地方...
# 打出来一些数据
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
"""
Epoch: 0 | Step: 0 | batch x: [ 6. 7. 2. 3. 1.] | batch y: [ 5. 4. 9. 8. 10.]
Epoch: 0 | Step: 1 | batch x: [ 9. 10. 4. 8. 5.] | batch y: [ 2. 1. 7. 3. 6.]
Epoch: 1 | Step: 0 | batch x: [ 3. 4. 2. 9. 10.] | batch y: [ 8. 7. 9. 2. 1.]
Epoch: 1 | Step: 1 | batch x: [ 1. 7. 8. 5. 6.] | batch y: [ 10. 4. 3. 6. 5.]
Epoch: 2 | Step: 0 | batch x: [ 3. 9. 2. 6. 7.] | batch y: [ 8. 2. 9. 5. 4.]
Epoch: 2 | Step: 1 | batch x: [ 10. 4. 8. 1. 5.] | batch y: [ 1. 7. 3. 10. 6.]
"""
训练优化
常见优化方法
- SGD
- Momentum
- RMSprop
- Adam
SGD
将数据分批放入神经网络训练
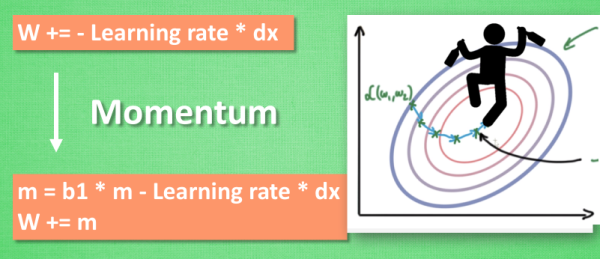
Momentum
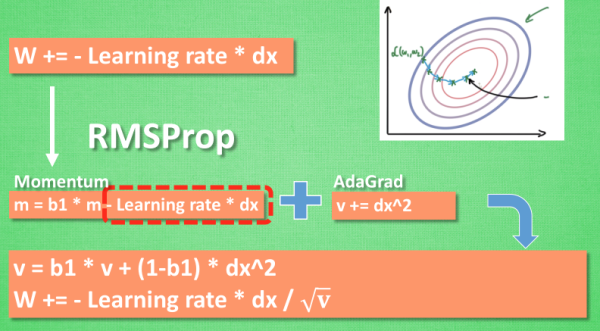
RMSprop
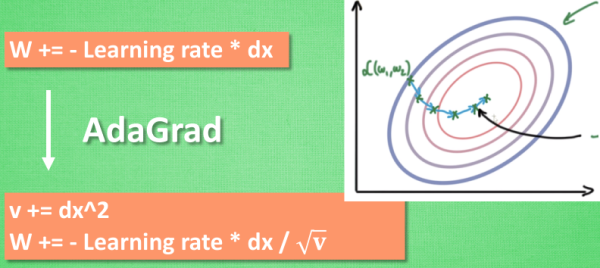
AdaGrad
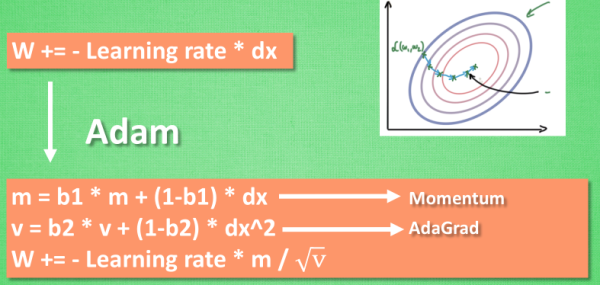
Adam
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
卷积神经网络搭建
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2, # 如果想要 con2d 出来的图片长宽没有变化, padding=(kernel_size-1)/2 当 stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # 在 2x2 空间里向下采样, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 展平多维的卷积图成 (batch_size, 32 * 7 * 7)
output = self.out(x)
循环神经网络搭建
RNN分类
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM( # LSTM 效果要比 nn.RNN() 好多了
input_size=28, # 图片每行的数据像素点
hidden_size=64, # rnn hidden unit
num_layers=1, # 有几层 RNN layers
batch_first=True, # input & output 会是以 batch size 为第一维度的特征集 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(64, 10) # 输出层
def forward(self, x):
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size) LSTM 有两个 hidden states, h_n 是分线, h_c 是主线
# h_c shape (n_layers, batch, hidden_size)
r_out, (h_n, h_c) = self.rnn(x, None) # None 表示 hidden state 会用全0的 state
# 选取最后一个时间点的 r_out 输出
# 这里 r_out[:, -1, :] 的值也是 h_n 的值
out = self.out(r_out[:, -1, :])
return out
RNN回归
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN( # 这回一个普通的 RNN 就能胜任
input_size=1,
hidden_size=32, # rnn hidden unit
num_layers=1, # 有几层 RNN layers
batch_first=True, # input & output 会是以 batch size 为第一维度的特征集 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(32, 1)
def forward(self, x, h_state): # 因为 hidden state 是连续的, 所以我们要一直传递这一个 state
# x (batch, time_step, input_size)
# h_state (n_layers, batch, hidden_size)
# r_out (batch, time_step, output_size)
r_out, h_state = self.rnn(x, h_state) # h_state 也要作为 RNN 的一个输入
outs = [] # 保存所有时间点的预测值
for time_step in range(r_out.size(1)): # 对每一个时间点计算 output
outs.append(self.out(r_out[:, time_step, :]))
return torch.stack(outs, dim=1), h_state
前向传播也可以简化为
def forward(self, x, h_state):
r_out, h_state = self.rnn(x, h_state)
r_out = r_out.view(-1, 32)
outs = self.out(r_out)
return outs.view(-1, 32, TIME_STEP), h_state
GPU加速
将变量移动到GPU
x.cuda()
计算图移动到GPU
net.cuda()
训练移动到GPU
pred_y = torch.max(test_output, 1)[1].cuda().data.squeeze() # 将操作放去 GPU
pytorch 的GPU编号从0开始,调用多GPU时要注意
dropout防止过拟合
无过拟合网络
net_overfitting = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
dropout网络
net_dropped = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.Dropout(0.5), # drop 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.Dropout(0.5), # drop 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
在使用预测时取出dropout
net_dropped.eval()
Batch Normalization归一化
Batch Normalization过程
class Net(nn.Module):
def __init__(self, batch_normalization=False):
super(Net, self).__init__()
self.do_bn = batch_normalization
self.fcs = [] # 太多层了, 我们用 for loop 建立
self.bns = []
self.bn_input = nn.BatchNorm1d(1, momentum=0.5) # 给 input 的 BN
for i in range(N_HIDDEN): # 建层
input_size = 1 if i == 0 else 10
fc = nn.Linear(input_size, 10)
setattr(self, 'fc%i' % i, fc) # 注意! pytorch 一定要你将层信息变成 class 的属性! 我在这里花了2天时间发现了这个 bug
self._set_init(fc) # 参数初始化
self.fcs.append(fc)
if self.do_bn:
bn = nn.BatchNorm1d(10, momentum=0.5)
setattr(self, 'bn%i' % i, bn) # 注意! pytorch 一定要你将层信息变成 class 的属性! 我在这里花了2天时间发现了这个 bug
self.bns.append(bn)
self.predict = nn.Linear(10, 1) # output layer
self._set_init(self.predict) # 参数初始化
def _set_init(self, layer): # 参数初始化
init.normal_(layer.weight, mean=0., std=.1)
init.constant_(layer.bias, B_INIT)
def forward(self, x):
pre_activation = [x]
if self.do_bn: x = self.bn_input(x) # 判断是否要加 BN
layer_input = [x]
for i in range(N_HIDDEN):
x = self.fcs[i](x)
pre_activation.append(x) # 为之后出图
if self.do_bn: x = self.bns[i](x) # 判断是否要加 BN
x = ACTIVATION(x)
layer_input.append(x) # 为之后出图
out = self.predict(x)
return out, layer_input, pre_activation
# 建立两个 net, 一个有 BN, 一个没有
nets = [Net(batch_normalization=False), Net(batch_normalization=True)]
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 摸黑干活!
相关推荐

评论