强化学习基础和马尔科夫决策过程
强化学习基本过程
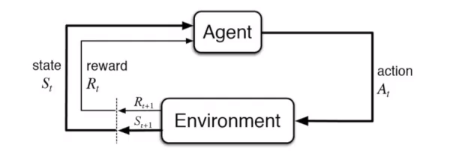
强化学习基本要素
- 模型
- 政策
- 价值
深度学习不同点
- 没有标签,只有反馈
- 学习的过程来自于试错
- 学习的反馈有延迟
- 动作会影响数据
- 观察数据有时间的关联
马尔科夫基本过程(MDP)
马尔科夫过程的下一状态只取决于当前状态
马尔科夫奖励过程
- S:state
- R: Reward,$R(s_t=s)$
- Discount factor $\gamma\in [0,1]$
- P:dynamics/transition model
Horizon
- Number of maximum time steps in each episode
- Can be infinite,otherwise called finite Markov (reward) Process
Return
可以看出随着时间变化,奖励值会衰减,只有离开某个状态才能获得奖励,所以奖励来自于未来的状态
state value function Vt(s) for a MRP
Expected
Discount Factor $\gamma$
可以作为强化学习的超参数调整
- 当$\gamma=0$,奖励只取决于当前状态
Bellman equation
Bellman方程描述了状态的迭代关系
也可以写为矩阵的形式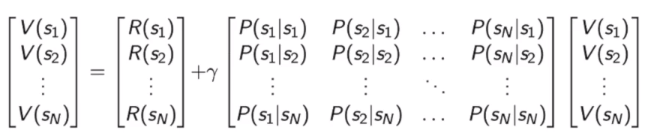
我们可以通过矩阵求逆的过程求出V
矩阵求逆的计算量太大,所以我们一般用迭代的方法求解
- 动态规划法
- 蒙特卡洛采样法
- Temporal-Difference learning
蒙特卡洛法

动态规划

马尔科夫决策过程
增加了一个动作
- S:state
- A: action
- R: Reward,$R(s_t=s)$
- Discount factor $\gamma\in [0,1]$
- P:dynamics/transition model $P(s_{t+1}=s’|s_t=s,a_t=a$
Policy
- policy决定了当前采取的策略
- Policy:$\pi(a|s)=P(a_t=a|a_t=s)$
- Policies are stationary (time-independent),$A_t~ \pi(a|s)$ for any t > 0
- Given an MDP $(S,A, P,R,\gamma)$ and a policy $\pi$
- The state sequence S1, S2,… is a Markov process $(S, P^\pi)$
- The state and reward sequence S1,R2,S2, R2,… is a Markov reward
process (S, PT,R”, ) where,
当policy$\pi$已知时,马尔科夫决策过程会转化为马尔科夫奖励过程
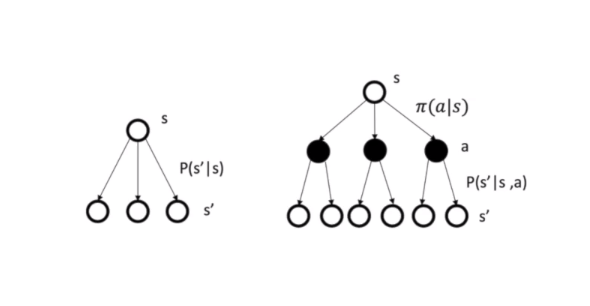
马尔科夫决策过程的下一状态先由当前状态采取的决策决定
State Value Function
action-value function
状态价值函数和动作价值函数的关系
Bellman Equation
$v^\pi$表示了采用policy$\pi$得到奖励的期望
马尔科夫决策过程的预测和控制
- 预测
- 预测价值
- 控制
- 寻找最佳策略
predition
尝试所有策略,收敛后得到价值函数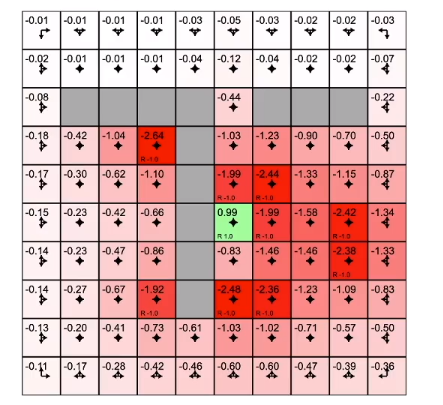
optimal value function and policy
如何寻找最佳的policy?
最佳行为可以定义为
policy search
策略搜索的方法主要有以下两种
policy iteration
策略迭代算法有两个步骤
- 估计当前政策价值函数
- 采用贪心算法改进策略
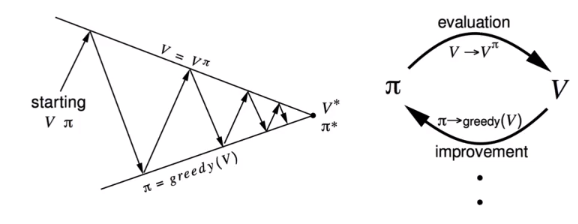
policy improvwment
- 计算当前策略价值
- 计算新政策价值
value iteration

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 摸黑干活!
相关推荐

评论