DQN实现机器人自动走迷宫
问题简介
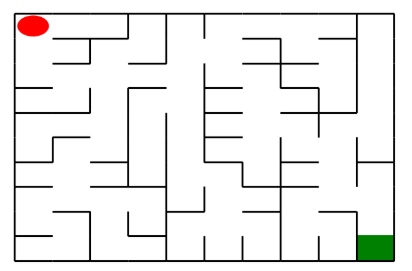
如上图所示,左上角的红色椭圆既是起点也是机器人的初始位置,右下角的绿色方块是出口。
游戏规则为:从起点开始,通过错综复杂的迷宫,到达目标点(出口)。
- 在任一位置可执行动作包括:向上走
'u'、向右走'r'、向下走'd'、向左走'l'。 - 执行不同的动作后,根据不同的情况会获得不同的奖励,具体而言,有以下几种情况。
- 撞墙
- 走到出口
- 其余情况
我们分别实现了基于基础搜索算法和 Deep QLearning 算法的机器人,使机器人自动走到迷宫的出口。
设计思想
Maze 类介绍
创建迷宫
通过迷宫类 Maze 可以随机创建一个迷宫。
- 使用 Maze(maze_size=size) 来随机生成一个 size * size 大小的迷宫。
- 使用 print() 函数可以输出迷宫的 size 以及画出迷宫图
- 红色的圆是机器人初始位置
- 绿色的方块是迷宫的出口位置
""" 创建迷宫并展示 """
maze = Maze(maze_size=10) # 随机生成迷宫
print(maze)
重要的成员方法
在迷宫中已经初始化一个机器人,你要编写的算法实现在给定条件下控制机器人移动至目标点。
Maze 类中重要的成员方法如下:
- sense_robot() :获取机器人在迷宫中目前的位置。
return:机器人在迷宫中目前的位置。
- move_robot(direction) :根据输入方向移动默认机器人,若方向不合法则返回错误信息。
direction:移动方向, 如:”u”, 合法值为: [‘u’, ‘r’, ‘d’, ‘l’]
return:执行动作的奖励值
- can_move_actions(position):获取当前机器人可以移动的方向
position:迷宫中任一处的坐标点
return:该点可执行的动作,如:[‘u’,’r’,’d’]
- is_hit_wall(self, location, direction):判断该移动方向是否撞墙
location, direction:当前位置和要移动的方向,如(0,0) , “u”
return:True(撞墙) / False(不撞墙)
- draw_maze():画出当前的迷宫
随机移动机器人,并记录下获得的奖励,展示出机器人最后的位置。
import random
rewards = [] # 记录每走一步的奖励值
actions = [] # 记录每走一步的移动方向
# 循环、随机移动机器人10次,记录下奖励
for i in range(10):
valid_actions = maze.can_move_actions(maze.sense_robot())
action = random.choice(valid_actions)
rewards.append(maze.move_robot(action))
actions.append(action)
print("the history of rewards:", rewards)
print("the actions", actions)
# 输出机器人最后的位置
print("the end position of robot:", maze.sense_robot())
# 打印迷宫,观察机器人位置
print(maze)
基础搜索算法介绍(广度优先搜索算法)
对于迷宫游戏,常见的三种的搜索算法有广度优先搜索、深度优先搜索和最佳优先搜索(A*)。
在下面的代码示例中,将实现广度优先搜索算法;主要通过建立一颗搜索树并进行层次遍历实现。
- 每个节点表示为以
Class SearchTree实例化的对象,类属性有:当前节点位置、到达当前节点的动作、当前节点的父节点、当前节点的子节点; valid_actions():用以获取机器人可以行走的位置(即不能穿墙);expand():对于未拓展的子节点进行拓展;backpropagation():回溯搜索路径。
算法具体步骤
首先以机器人起始位置建立根节点,并入队;接下来不断重复以下步骤直到判定条件:
- 将队首节点的位置标记已访问;判断队首是否为目标位置(出口), 是 则终止循环并记录回溯路径
- 判断队首节点是否为叶子节点,是 则拓展该叶子节点
- 如果队首节点有子节点,则将每个子节点插到队尾
- 将队首节点出队
实现广度优先搜索算法
import numpy as np
# 机器人移动方向
move_map = {
'u': (-1, 0), # up
'r': (0, +1), # right
'd': (+1, 0), # down
'l': (0, -1), # left
}
# 迷宫路径搜索树
class SearchTree(object):
def __init__(self, loc=(), action='', parent=None):
"""
初始化搜索树节点对象
:param loc: 新节点的机器人所处位置
:param action: 新节点的对应的移动方向
:param parent: 新节点的父辈节点
"""
self.loc = loc # 当前节点位置
self.to_this_action = action # 到达当前节点的动作
self.parent = parent # 当前节点的父节点
self.children = [] # 当前节点的子节点
def add_child(self, child):
"""
添加子节点
:param child:待添加的子节点
"""
self.children.append(child)
def is_leaf(self):
"""
判断当前节点是否是叶子节点
"""
return len(self.children) == 0
def expand(maze, is_visit_m, node):
"""
拓展叶子节点,即为当前的叶子节点添加执行合法动作后到达的子节点
:param maze: 迷宫对象
:param is_visit_m: 记录迷宫每个位置是否访问的矩阵
:param node: 待拓展的叶子节点
"""
can_move = maze.can_move_actions(node.loc)
for a in can_move:
new_loc = tuple(node.loc[i] + move_map[a][i] for i in range(2))
if not is_visit_m[new_loc]:
child = SearchTree(loc=new_loc, action=a, parent=node)
node.add_child(child)
def back_propagation(node):
"""
回溯并记录节点路径
:param node: 待回溯节点
:return: 回溯路径
"""
path = []
while node.parent is not None:
path.insert(0, node.to_this_action)
node = node.parent
return path
def breadth_first_search(maze):
"""
对迷宫进行广度优先搜索
:param maze: 待搜索的maze对象
"""
start = maze.sense_robot()
root = SearchTree(loc=start)
queue = [root] # 节点队列,用于层次遍历
h, w, _ = maze.maze_data.shape
is_visit_m = np.zeros((h, w), dtype=np.int) # 标记迷宫的各个位置是否被访问过
path = [] # 记录路径
while True:
current_node = queue[0]
is_visit_m[current_node.loc] = 1 # 标记当前节点位置已访问
if current_node.loc == maze.destination: # 到达目标点
path = back_propagation(current_node)
break
if current_node.is_leaf():
expand(maze, is_visit_m, current_node)
# 入队
for child in current_node.children:
queue.append(child)
# 出队
queue.pop(0)
return path
测试广度优先搜索算法
maze = Maze(maze_size=10)
height, width, _ = maze.maze_data.shape
path_1 = breadth_first_search(maze)
print("搜索出的路径:", path_1)
for action in path_1:
maze.move_robot(action)
if maze.sense_robot() == maze.destination:
print("恭喜你,到达了目标点")
print(maze)
深度优先搜索算法
输入:迷宫
输出:到达目标点的路径
def my_search(maze):
"""
对迷宫实现深度优先搜索算法
:param maze: 迷宫对象
:return :到达目标点的路径 如:["u","u","r",...]
"""
start = maze.sense_robot()
root = SearchTree(loc=start)
h, w, _ = maze.maze_data.shape
is_visit_m = np.zeros((h, w), dtype=np.int) # 标记迷宫的各个位置是否被访问过
path = [] # 记录路径
path = dfs(maze, is_visit_m, root)
return path
def dfs(maze, is_visit_m, current_node):
if current_node.loc == maze.destination: # 到达目标点
path = back_propagation(current_node)
return path
elif current_node.is_leaf():
expand(maze, is_visit_m, current_node)
for node in current_node.children:
is_visit_m[node.loc] = 1
path = dfs(maze, is_visit_m, node)
if not path == None:
return path
else:
return None
测试深度优先算法
maze = Maze(maze_size=10) # 从文件生成迷宫
path_2 = my_search(maze)
print("搜索出的路径:", path_2)
for action in path_2:
maze.move_robot(action)
if maze.sense_robot() == maze.destination:
print("恭喜你,到达了目标点")
强化学习算法介绍
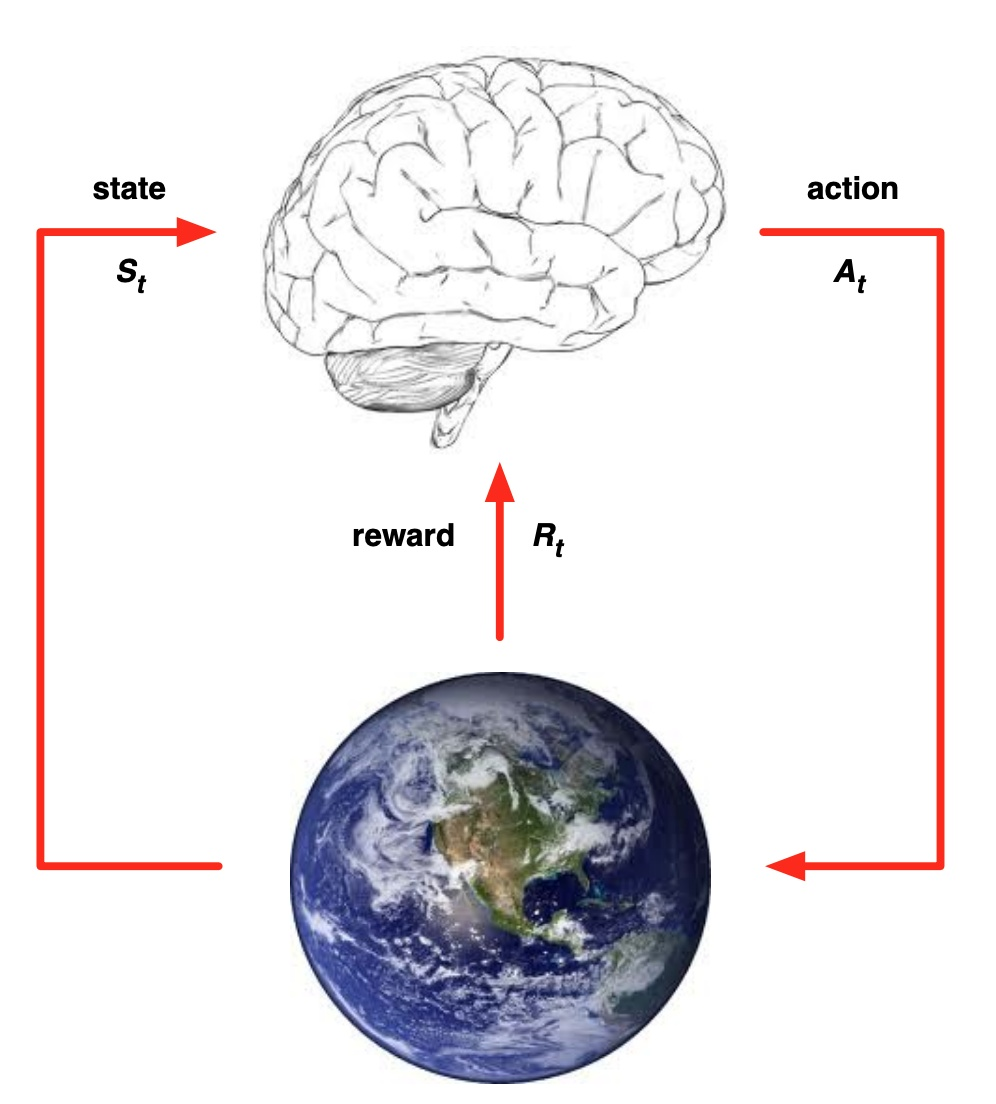
强化学习作为机器学习算法的一种,其模式也是让智能体在“训练”中学到“经验”,以实现给定的任务。但不同于监督学习与非监督学习,在强化学习的框架中,我们更侧重通过智能体与环境的交互来学习。通常在监督学习和非监督学习任务中,智能体往往需要通过给定的训练集,辅之以既定的训练目标(如最小化损失函数),通过给定的学习算法来实现这一目标。然而在强化学习中,智能体则是通过其与环境交互得到的奖励进行学习。这个环境可以是虚拟的(如虚拟的迷宫),也可以是真实的(自动驾驶汽车在真实道路上收集数据)。
在强化学习中有五个核心组成部分,它们分别是:环境(Environment)、智能体(Agent)、状态(State)、动作(Action)和奖励(Reward)。
在某一时间节点 $t$:
- 智能体在从环境中感知其所处的状态 $s_t$
- 智能体根据某些准则选择动作 $a_t$
- 环境根据智能体选择的动作,向智能体反馈奖励 $r_{t+1}$
通过合理的学习算法,智能体将在这样的问题设置下,成功学到一个在状态 $s_t$ 选择动作 $a_t$ 的策略 $\pi (s_t) = a_t$。
QLearning 算法
Q-Learning 是一个值迭代(Value Iteration)算法。
与策略迭代(Policy Iteration)算法不同,值迭代算法会计算每个”状态“或是”状态-动作“的值(Value)或是效用(Utility),然后在执行动作的时候,会设法最大化这个值。
因此,对每个状态值的准确估计,是值迭代算法的核心。
通常会考虑最大化动作的长期奖励,即不仅考虑当前动作带来的奖励,还会考虑动作长远的奖励。
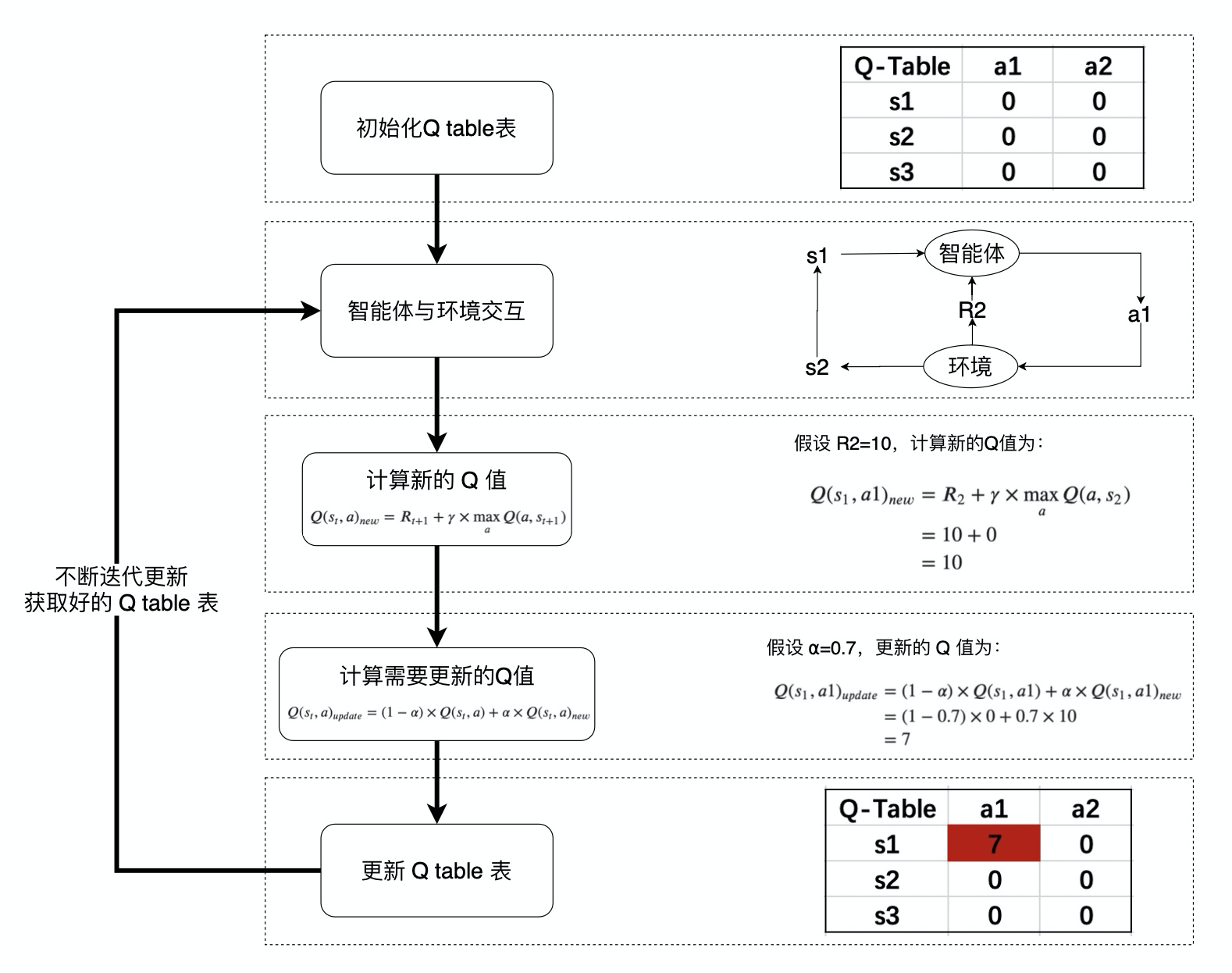
Q 值的计算与迭代
Q-learning 算法将状态(state)和动作(action)构建成一张 Q_table 表来存储 Q 值,Q 表的行代表状态(state),列代表动作(action):
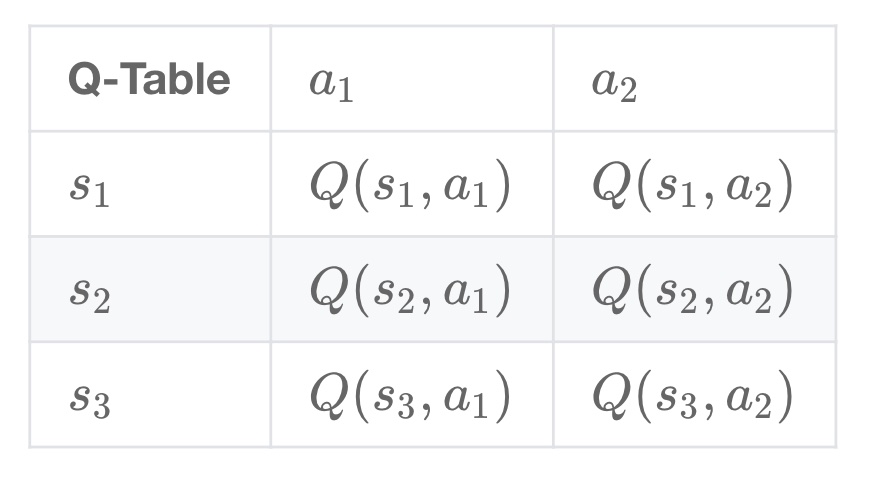
在 Q-Learning 算法中,将这个长期奖励记为 Q 值,其中会考虑每个 ”状态-动作“ 的 Q 值,具体而言,它的计算公式为:
也就是对于当前的“状态-动作” $(s{t},a)$,考虑执行动作 $a$ 后环境奖励 $R{t+1}$,以及执行动作 $a$ 到达 $s{t+1}$后,执行任意动作能够获得的最大的Q值 $\max_a Q(a,s{t+1})$,$\gamma$ 为折扣因子。
计算得到新的 Q 值之后,一般会使用更为保守地更新 Q 表的方法,即引入松弛变量 $alpha$ ,按如下的公式进行更新,使得 Q 表的迭代变化更为平缓。
机器人动作的选择
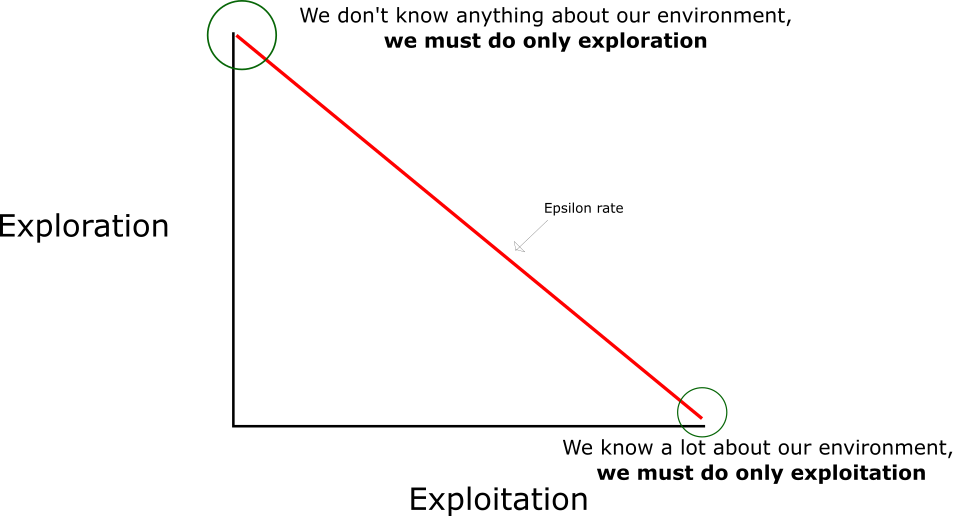
在强化学习中,探索-利用 问题是非常重要的问题。
具体来说,根据上面的定义,会尽可能地让机器人在每次选择最优的决策,来最大化长期奖励。
但是这样做有如下的弊端:
- 在初步的学习中,Q 值是不准确的,如果在这个时候都按照 Q 值来选择,那么会造成错误。
- 学习一段时间后,机器人的路线会相对固定,则机器人无法对环境进行有效的探索。
因此需要一种办法,来解决如上的问题,增加机器人的探索。
通常会使用 epsilon-greedy 算法:
- 在机器人选择动作的时候,以一部分的概率随机选择动作,以一部分的概率按照最优的 Q 值选择动作。
- 同时,这个选择随机动作的概率应当随着训练的过程逐步减小。
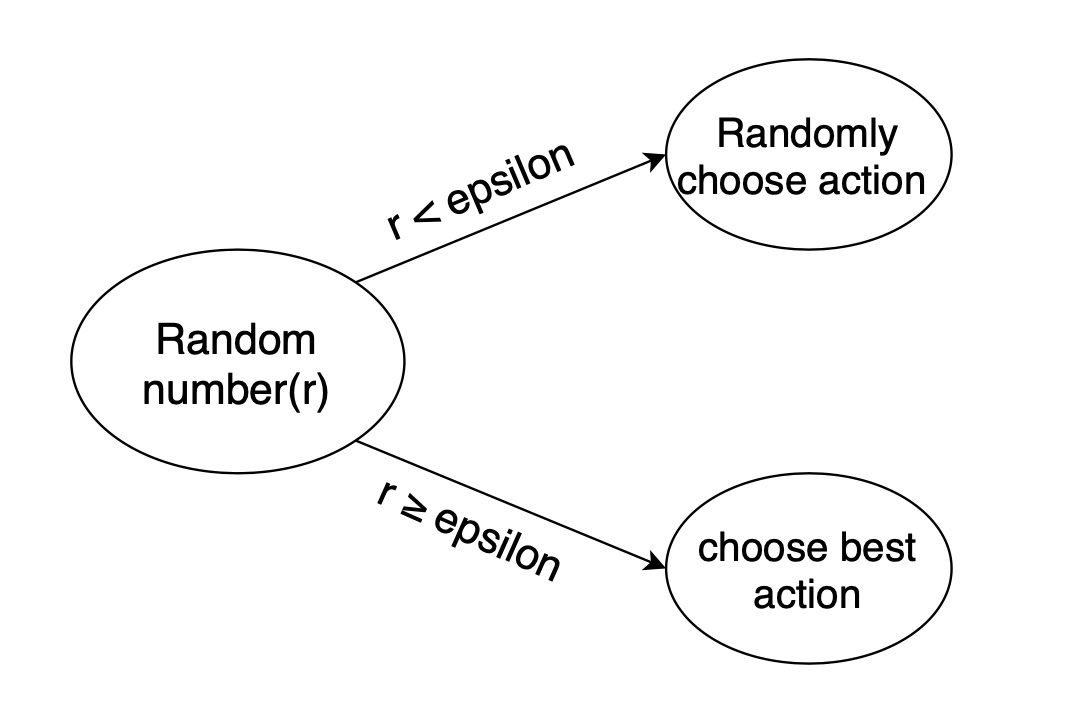
Q-Learning 算法的学习过程
QRobot 类
QRobot 类,其中实现了 Q 表迭代和机器人动作的选择策略,可通过 from QRobot import QRobot 导入使用。
QRobot 类的核心成员方法
- sense_state():获取当前机器人所处位置
return:机器人所处的位置坐标,如: (0, 0)
- current_state_valid_actions():获取当前机器人可以合法移动的动作
return:由当前合法动作组成的列表,如: [‘u’,’r’]
- train_update():以训练状态,根据 QLearning 算法策略执行动作
return:当前选择的动作,以及执行当前动作获得的回报, 如: ‘u’, -1
- test_update():以测试状态,根据 QLearning 算法策略执行动作
return:当前选择的动作,以及执行当前动作获得的回报, 如:’u’, -1
- reset()
return:重置机器人在迷宫中的位置
from QRobot import QRobot
from Maze import Maze
maze = Maze(maze_size=5) # 随机生成迷宫
robot = QRobot(maze) # 记得将 maze 变量修改为你创建迷宫的变量名
action, reward = robot.train_update() # QLearning 算法一次Q值迭代和动作选择
print("the choosed action: ", action)
print("the returned reward: ", action)
Runner 类
QRobot 类实现了 QLearning 算法的 Q 值迭代和动作选择策略。在机器人自动走迷宫的训练过程中,需要不断的使用 QLearning 算法来迭代更新 Q 值表,以达到一个“最优”的状态,因此封装好了一个类 Runner 用于机器人的训练和可视化。可通过 from Runner import Runner 导入使用。
Runner 类的核心成员方法:
- run_training(training_epoch, training_per_epoch=150): 训练机器人,不断更新 Q 表,并讲训练结果保存在成员变量 train_robot_record 中
training_epoch, training_per_epoch: 总共的训练次数、每次训练机器人最多移动的步数
run_testing():测试机器人能否走出迷宫
generate_gif(filename):将训练结果输出到指定的 gif 图片中
filename:合法的文件路径,文件名需以
.gif为后缀
- plot_results():以图表展示训练过程中的指标:Success Times、Accumulated Rewards、Runing Times per Epoch
设定训练参数、训练、查看结果
from QRobot import QRobot
from Maze import Maze
from Runner import Runner
""" Qlearning 算法相关参数: """
epoch = 10 # 训练轮数
epsilon0 = 0.5 # 初始探索概率
alpha = 0.5 # 公式中的 ⍺
gamma = 0.9 # 公式中的 γ
maze_size = 5 # 迷宫size
""" 使用 QLearning 算法训练过程 """
g = Maze(maze_size=maze_size)
r = QRobot(g, alpha=alpha, epsilon0=epsilon0, gamma=gamma)
runner = Runner(r)
runner.run_training(epoch, training_per_epoch=int(maze_size * maze_size * 1.5))
# 生成训练过程的gif图, 建议下载到本地查看;也可以注释该行代码,加快运行速度。
runner.generate_gif(filename="results/size5.gif")
runner.plot_results() # 输出训练结果,可根据该结果对您的机器人进行分析。
实现 Deep QLearning 算法
DQN 算法介绍
强化学习是一个反复迭代的过程,每一次迭代要解决两个问题:给定一个策略求值函数,和根据值函数来更新策略。而 DQN 算法使用神经网络来近似值函数。(DQN 论文地址)
- DQN 算法流程

- DQN 算法框架图
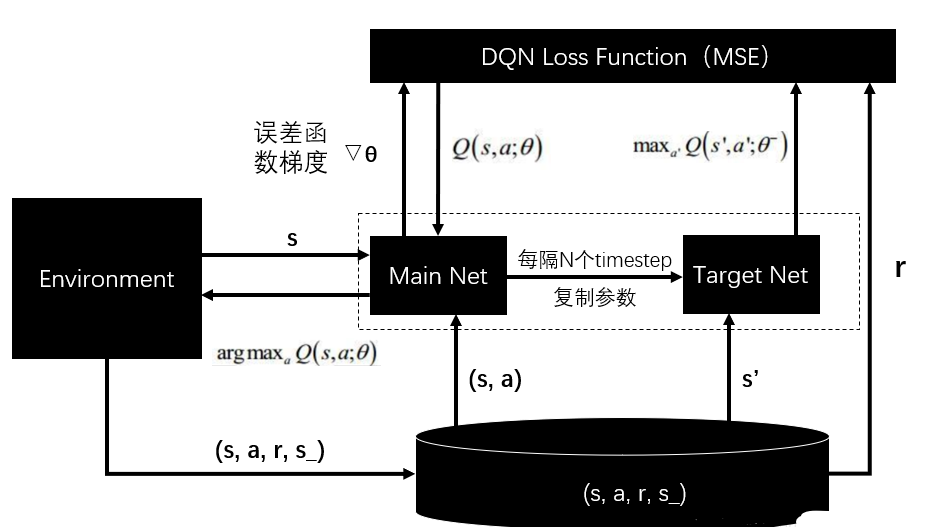
完成 DQN 算法
ReplayDataSet 类的核心成员方法
- add(self, state, action_index, reward, next_state, is_terminal) 添加一条训练数据
state: 当前机器人位置
action_index: 选择执行动作的索引
reward: 执行动作获得的回报
next_state:执行动作后机器人的位置
is_terminal:机器人是否到达了终止节点(到达终点或者撞墙)
- random_sample(self, batch_size):从数据集中随机抽取固定batch_size的数据
batch_size: 整数,不允许超过数据集中数据的个数
- build_full_view(self, maze):开启金手指,获取全图视野
maze: 以 Maze 类实例化的对象
"""ReplayDataSet 类的使用"""
from ReplayDataSet import ReplayDataSet
test_memory = ReplayDataSet(max_size=1e3) # 初始化并设定最大容量
actions = ['u', 'r', 'd', 'l']
test_memory.add((0,1), actions.index("r"), -10, (0,1), 1) # 添加一条数据(state, action_index, reward, next_state)
print(test_memory.random_sample(1)) # 从中随机抽取一条(因为只有一条数据)
实现DQNRobot
- 输入: 由 Maze 类实例化的对象 maze
from QRobot import QRobot
class Robot(QRobot):
valid_action = ['u', 'r', 'd', 'l']
''' QLearning parameters'''
epsilon0 = 0.5 # 初始贪心算法探索概率
gamma = 0.94 # 公式中的 γ
EveryUpdate = 1 # the interval of target model's updating
"""some parameters of neural network"""
target_model = None
eval_model = None
batch_size = 32
learning_rate = 1e-2
TAU = 1e-3
step = 1 # 记录训练的步数
"""setting the device to train network"""
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
def __init__(self, maze):
"""
初始化 Robot 类
:param maze:迷宫对象
"""
super(Robot, self).__init__(maze)
maze.set_reward(reward={
"hit_wall": 10.,
"destination": -50.,
"default": 1.,
})
self.maze = maze
self.maze_size = maze.maze_size
"""build network"""
self.target_model = None
self.eval_model = None
self._build_network()
"""create the memory to store data"""
max_size = max(self.maze_size ** 2 * 3, 1e4)
self.memory = ReplayDataSet(max_size=max_size)
def _build_network(self):
seed = 0
random.seed(seed)
"""build target model"""
self.target_model = QNetwork(state_size=2, action_size=4, seed=seed).to(self.device)
"""build eval model"""
self.eval_model = QNetwork(state_size=2, action_size=4, seed=seed).to(self.device)
"""build the optimizer"""
self.optimizer = optim.Adam(self.eval_model.parameters(), lr=self.learning_rate)
def target_replace_op(self):
"""
Soft update the target model parameters.
θ_target = τ*θ_local + (1 - τ)*θ_target
"""
# for target_param, eval_param in zip(self.target_model.parameters(), self.eval_model.parameters()):
# target_param.data.copy_(self.TAU * eval_param.data + (1.0 - self.TAU) * target_param.data)
""" replace the whole parameters"""
self.target_model.load_state_dict(self.eval_model.state_dict())
def _choose_action(self, state):
state = np.array(state)
state = torch.from_numpy(state).float().to(self.device)
if random.random() < self.epsilon:
action = random.choice(self.valid_action)
else:
self.eval_model.eval()
with torch.no_grad():
q_next = self.eval_model(state).cpu().data.numpy() # use target model choose action
self.eval_model.train()
action = self.valid_action[np.argmin(q_next).item()]
return action
def _learn(self, batch: int = 16):
if len(self.memory) < batch:
print("the memory data is not enough")
return
state, action_index, reward, next_state, is_terminal = self.memory.random_sample(batch)
""" convert the data to tensor type"""
state = torch.from_numpy(state).float().to(self.device)
action_index = torch.from_numpy(action_index).long().to(self.device)
reward = torch.from_numpy(reward).float().to(self.device)
next_state = torch.from_numpy(next_state).float().to(self.device)
is_terminal = torch.from_numpy(is_terminal).int().to(self.device)
self.eval_model.train()
self.target_model.eval()
"""Get max predicted Q values (for next states) from target model"""
Q_targets_next = self.target_model(next_state).detach().min(1)[0].unsqueeze(1)
"""Compute Q targets for current states"""
Q_targets = reward + self.gamma * Q_targets_next * (torch.ones_like(is_terminal) - is_terminal)
"""Get expected Q values from local model"""
self.optimizer.zero_grad()
Q_expected = self.eval_model(state).gather(dim=1, index=action_index)
"""Compute loss"""
loss = F.mse_loss(Q_expected, Q_targets)
loss_item = loss.item()
""" Minimize the loss"""
loss.backward()
self.optimizer.step()
"""copy the weights of eval_model to the target_model"""
self.target_replace_op()
return loss_item
def train_update(self):
"""
以训练状态选择动作并更新Deep Q network的相关参数
:return :action, reward 如:"u", -1
"""
state = self.sense_state()
action = self._choose_action(state)
reward = self.maze.move_robot(action)
next_state = self.sense_state()
is_terminal = 1 if next_state == self.maze.destination or next_state == state else 0
self.memory.add(state, self.valid_action.index(action), reward, next_state, is_terminal)
"""--间隔一段时间更新target network权重--"""
if self.step % self.EveryUpdate == 0:
self._learn(batch=32)
"""---update the step and epsilon---"""
self.step += 1
self.epsilon = max(0.01, self.epsilon * 0.995)
return action, reward
def test_update(self):
"""
以测试状态选择动作并更新Deep Q network的相关参数
:return : action, reward 如:"u", -1
"""
state = np.array(self.sense_state(), dtype=np.int16)
state = torch.from_numpy(state).float().to(self.device)
self.eval_model.eval()
with torch.no_grad():
q_value = self.eval_model(state).cpu().data.numpy()
action = self.valid_action[np.argmin(q_value).item()]
reward = self.maze.move_robot(action)
return action, reward
测试 DQN 算法
from QRobot import QRobot
from Maze import Maze
from Runner import Runner
""" Deep Qlearning 算法相关参数: """
epoch = 10 # 训练轮数
maze_size = 5 # 迷宫size
training_per_epoch=int(maze_size * maze_size * 1.5)
""" 使用 DQN 算法训练 """
g = Maze(maze_size=maze_size)
r = Robot(g)
runner = Runner(r)
runner.run_training(epoch, training_per_epoch)
# 生成训练过程的gif图, 建议下载到本地查看;也可以注释该行代码,加快运行速度。
runner.generate_gif(filename="results/dqn_size10.gif")
实验结果
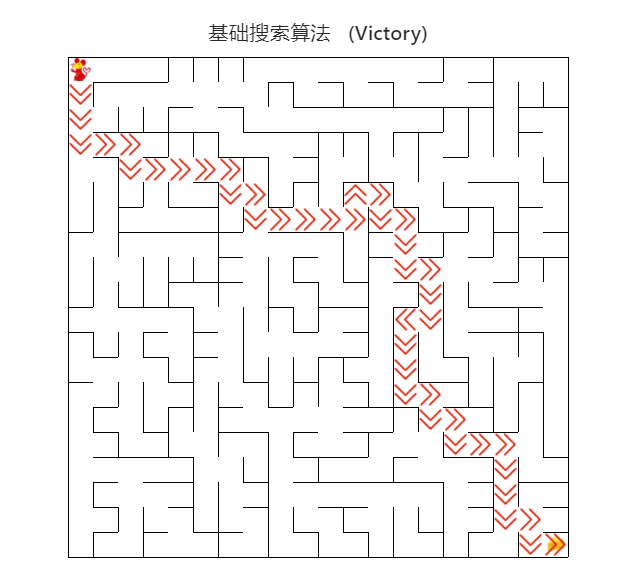
基础搜索算法
深度强化学习算法