论文解读:OPTIMIZER FUSION - EFFICIENT TRAINING WITH BETTER LOCALITY AND PARALLELISM
OPTIMIZER FUSION: EFFICIENT TRAINING WITH BETTER LOCALITY AND PARALLELISM
2021 ICLR的文章,来自德克萨斯奥斯汀,提出了一种针对大规模训练的优化器融合训练方法。
Absract
机器学习框架采用迭代优化器的方式来训练神经网络。传统的Eager execution的训练方式将可训练参数的更新与前向和后向计算分开。然而,这样的方式由于缺乏对数据本地性(data locality)和计算并行性(computation parallelism)的利用,引入了不可忽视的训练时间开销。在这项工作中,我们通过将优化器与前向或后向计算融合在一起,来更好地利用训练中的数据本地性和计算并行性。通过重新安排前向传播、梯度计算和参数更新的顺序,我们可以在不同的配置上的减少高达20%训练时间。由于我们的方法没有改变优化器的算法。这个方法可以被用作训练过程中的一个一般 “插件 “来应用。
论文解决什么问题?
随机梯度下降和其变种是现在深度学习框架中主流的优化算法,Pytorch,TensorFlow,MXnet等框架通过对各个计算操作的自动微分来实现梯度的传播
Eager Execution(动态图模式)因其灵活性而在这些框架中被广泛采用。它通常将前向传播、梯度计算和参数更新为三个独立的阶段。在每次迭代中,首先执行前向计算。然后计算所有可学习参数的损失函数对应的梯度。最后,由一个指定的优化器来更新可学习的参数。尽管这个实现有一个直观和透明的过程,但可学习参数及其梯度在一次训练迭代中被读写多次,这样这些数据就不能被有效地重复使用。此外,梯度更新依赖于梯度计算,从而导致程序执行中的并行性降低。简而言之,在Eager Execution中有的对数据局部性和计算并行性的很大对提升潜力。
在本工作中,作者提出了前向融合和后向融合两种方法,即对前向计算、梯度计算和参数更新进行重新排序,以加速Eager Execution的训练过程。作者提出的方法将优化器与正向或向后计算相结合, 以更好地利用局部性和并行性。反向融合方法,由静态计算图编译驱动,其中优化器与梯度计算融合,尽早更新参数。正向融合方法将参数更新与下一个正融合计算融合,从而尽可能晚地更新可学习参数。
什么是Eager Execution?TensorFlow 的 Eager Execution 是一种命令式编程环境,(其实就是TensorFlow的动态图模式,pytorch作为一个动态图框架,本身就是Eager Execution模式)可立即评估操作,无需构建图:操作会返回具体的值,而不是构建以后再运行的计算图。使用静态图模式的TensorFlow通常要先构建计算图,再调用tf.Session对象的run方法。Eager Execution Google 官方博客解释
文章作出的贡献
文章提出的训练方法的恭喜主要有以下三点
- 高效性:文章的框架可以提高高达20%的训练速度。
- 通用性:文章的方法在保留Eager Execution所有特征的情况下,可以与其他优化方法一起使用,不影响训练结果。
- 易用性:用户只需要很少的工程量就可以采用文章的方法来加速他们的训练。
问题的背景:计算图和图优化
计算图分类
深度学习框架对计算图分为两类动态图和静态图。静态图将一个模型编译为一个静态的(计算图,并使用所有的神经网络信息来执行该图。例如,TensorFlow1.X 默认遵循这个例 程,这在执行之前需要一个预编译的图。动态图在Eager Execution(命令式)模 式下工作,该模式立即执行新遇到的计算节点,并逐步构建一个动态计算图。在每一步中,一个 计算节点被附加到当前的计算图中。PyTorch和 TensorFlow2,在默认情况下以Eager Execution 模式运行,使用户能够更容易和快速地开发机器学习模型。
图优化
机器学习框架中的工程师和从业者已经提出并实现了许多计算图优化器,但现有的图优化器需要整个计算图的信息,这意味着优化器融合只能用于(1)静态计算或(2)用于静态和动态执行的混合。在大多数机器学习框架中,纯Eager Execution(动态图)模式仍 然将前向计算、向后向传递和参数更新划分为三个阶段。
问题的解决方案:前向融合和后向融合
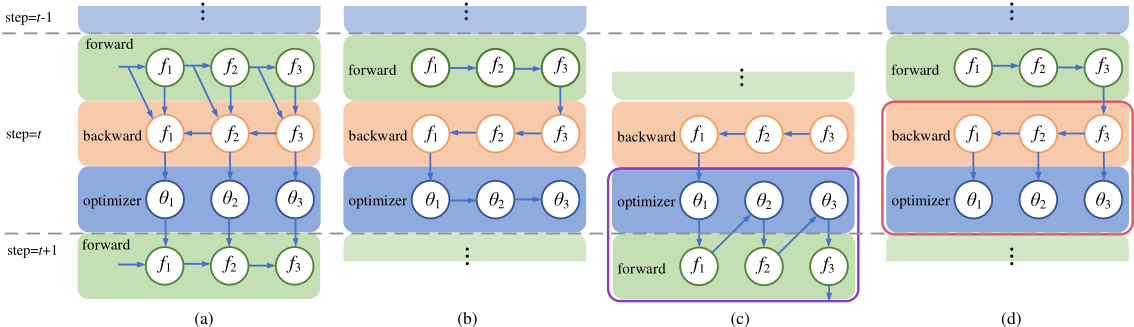
下面四张拓扑图分别表示了有数据依赖的训练过程,基础的动态图训练过程,前向融合和后向融合。代表第i层网络,代表第i层的参数。
基础训练方案的问题
上图(b)表示了基础的训练过程,分为这么几步:
- 读取模型参数
- 正向传播
- 计算Loss
- 反向传播,累计梯度
- 优化器读取梯度和模型参数并进行更新。
- 优化器重置梯度
- 优化器更新历史参数比如Momentum,Mean。
- 重复上述过程
数据局部性(data locality)
上述过程中所有内存读取的过程在前向和反向传播,优化器更新参数过程这三个过程中是彼此独立的,没有很好地利用数据的局部性,下图表示了这三个过程中读写操作的重叠部分,我们完全可以利用好这些重叠来减少数据读取到内存的时间。
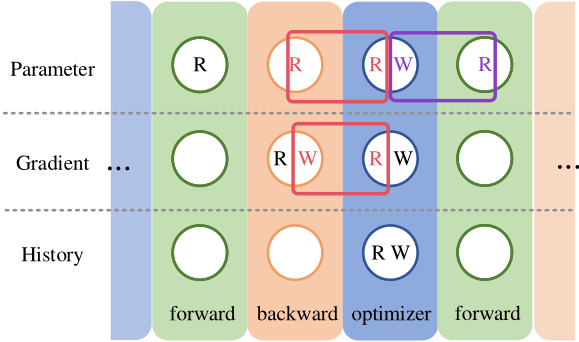
计算并行性(computation parallelism)
基础训练方案也没有利用好反向传播和参数更新 之间的并行性。在更新一组参数的同时,我们可以继续反向传播,同时计算其他参数的 梯度。
前向融合
前向融合的过程如下图(c)所示,其利用上图紫色框中对内存的重复利用,将一次数据优化器迭代和前向传播相结合
反向融合
反向融合将合并来一层网络反向传播和更新参数对内存对读取,如上图(d)所示,利用到来红色框中对数据局部性,同时这一操作实现来计算对并行性
三种方法比较
| 方法 | 数据局部性 | 计算并行性 | 全局信息 |
|---|---|---|---|
| baseline | × ️ | × | ✔ |
| 前向融合 | ✔ | × | ✔ |
| 反向融合 | ✔ | ✔ | × |
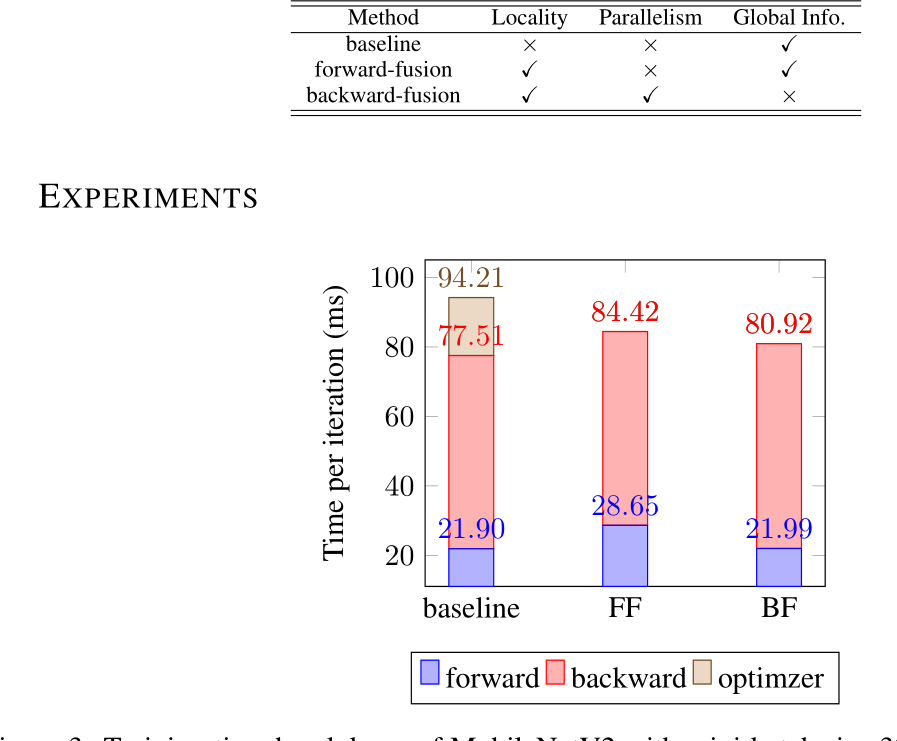
实验结果和结论
实验将MobileNetV2的一次训练迭代的时间分解,batch size大小为 32。
结果如下图所示,可以看出反向融合和前向融合比baseline的时间有显著减少。