Pytorch Distributed Data Parallal
目前有不少博客都有对pytorch Distirbuted data parallel的介绍和使用,但大多是针对实际代码的使用,本篇文章更侧重Pytorch DDP论文中提到的低层机制的实现以及目前存在的一些问题。
数据并行基本概念(Data Parallel)
如果工作节点没有共享的公共内存,只有容量受限的本地内存,而训练数据的规模很大,无法存储于本地内存,我们就需要对数据集进行划分,分配到各个工作节点上,然后工作节点依据各自分配的局部数据对模型进行训练 我们称此种并行模式为“数据并行模式。
数据并行的两种基本方式
随机采样
把原始训练数据集作为采样的数据集,通过有放回的方式进行随机采样,然后根据每个工作节点的内存容量为其分配相应数目的训练样本。随机采样方法可以保证每台机器上的局部训练数据与原始训练数据是独立同分布的。
置乱切分
将训练数据进行随机置乱,然后按照工作节点的个数将打乱后的数据顺序划分成相应的小份,随后将这些小份数据分配到各个工作节点上。每个工作节点在进行模型训练的过程中,只利用分配给向己的局部数据,并且会定期地(如每完成一个训练周期之后)将局部数据再打乱次 。 到一定阶段(如l完成多个训练周期之后),还可能再重新进行全局的数据打乱和重新分配 。
数据并行要求
- 数学上等价:必须在数学上可以证明本地训练和数据并行训练对模型结果的影响是一致的
- 非侵入和截断的 API:一般都是从本地开发然后扩展到分布式。API 需要允许内部实现可以即时拦截信号来做通信和系统优化
- 高性能:数据并行训练受到计算和通信之间依赖关系的限制,所以设计和实现必须平衡两者之间的关系。
Pytorch 分布式数据并行(Distributed Data Parallel)
DDP的原理
DP模式是很早就出现的、单机多卡的、参数服务器架构的多卡训练模式,在PyTorch,即是:
model = torch.nn.DataParallel(model)
在DP模式中,总共只有一个进程。master节点相当于参数服务器,其会向其他卡广播其参数;在梯度反向传播后,各卡将梯度集中到master节点,master节点对搜集来的参数进行平均后更新参数,再将参数统一发送到其他卡上。这种参数更新方式,会导致master节点的计算任务、通讯量很重,从而导致网络阻塞,降低训练速度。
在分类上,DDP 属于Data Parallel。简单来讲,DDP就是在每个计算节点上复制模型,并独立地生成梯度,然后在每次迭代中互相传递这些梯度并同步,以保持各节点模型的一致性
在Pytorch中DP和DDP的区别总结如下
| 方法 | 进程和线程 | 设备 | 模型副本数量 |
|---|---|---|---|
| Data Parallel | 单进程多线程 | 使用同一个机器上的多块卡 | 一个模型 |
| Distributed Data Parallel | 多进程 | 使用多个设备和其上的多个GPU | 每台设备上一个模型副本 |
对于分布式数据并行,其核心问题在于如何保持每个设备上模型的一致性以及计算和通信效率的平衡
保持数据一致性两种方式
参数平均
参数平均则直接计算所有模型参数的平均值。参数平均的操作在优化器执行梯度下降后,这意味着其可以作为一个辅助步骤,非常的灵活,但是参数存在一定问题:
- 数学上不等价
- 各批次数据的梯度下降方向不同,不利于收敛
- 计算和通信低效,两个阶段无法重叠
所以Pytorch的DDP设计中放弃了参数平均的方式。
梯度平均
梯度平均是将各个设备的梯度求平均,然后将这个平均梯度在各个节点的模型上作更新,这样的方式一方面在数学上和本地训练完全等价,而且可以实现异步,比参数平均更加高效。
ALL Reduce
AllReduce是实现梯度平均最简单的方法。AllReduce是分布式数据并行用于计算所有进程的梯度总和的原始通信API。它由多个通信库支持,包括NCCL[2]、Gloo[1]和MPI[4]。AllReduce操作期望每个进程提供一个相同大小的张量,共同将给定的算术操作(例如,求和、平均、最小、最大)。最简单的实现方法是让每个进程将其输入张量广播给其他进程,然后每个进程独立地进行算术运算后进行梯度下降来更新模型参数。
ALLReduce的改进算法
- RingALLReduce
- TreeAllReduce
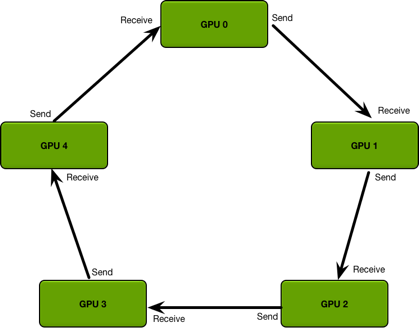
pytorch中实现DDP实际使用RingALLReduce实现AllReduce算法,Ring AllReduce的通信成本是恒定的,与 GPU 数量无关,其流程如下,具体细节本文不做过多介绍,可以参考
ring allreduce和tree allreduce的具体区别是什么?。
ALLReduce 存在问题
- 集合通信在小张量上表现较差,这在具有大量小参数的大模型上尤为突出。
- 梯度计算和同步分离开,就没有机会把计算和通信过程重叠到一起
梯度分桶(Gradient Bucketing)
Pytorch DDP设计最核心的机制就是Gradient Bucketing,其解决了直接ALLreduce存在的问题
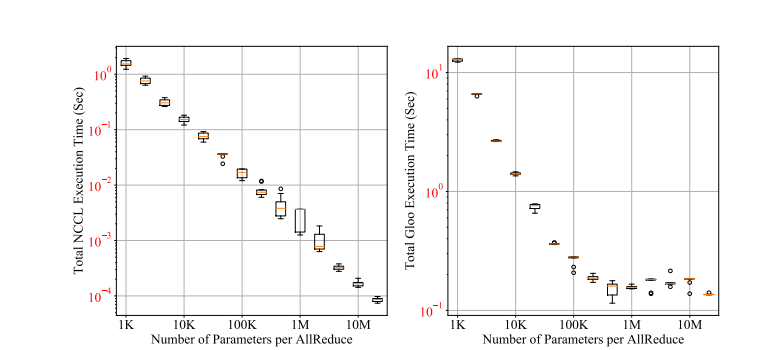
上图是ALLreduce执行时间和Tensor大小之间关系,从图中可以看出传递Tensor的参数越多,效率越高,这是梯度分桶的思想来源,既然每次传递小Tensor效率低,为什么不将多个参数的梯度聚合后传递?所以梯度分桶的做法将模型的Model的参数逆序插入每个Bucket中,当一个Bucket的参数的梯度都已经更新时,开启Allreduce,向另一个节点的对应Bucket传递梯度,这样也同时实现了异步AllReduce。
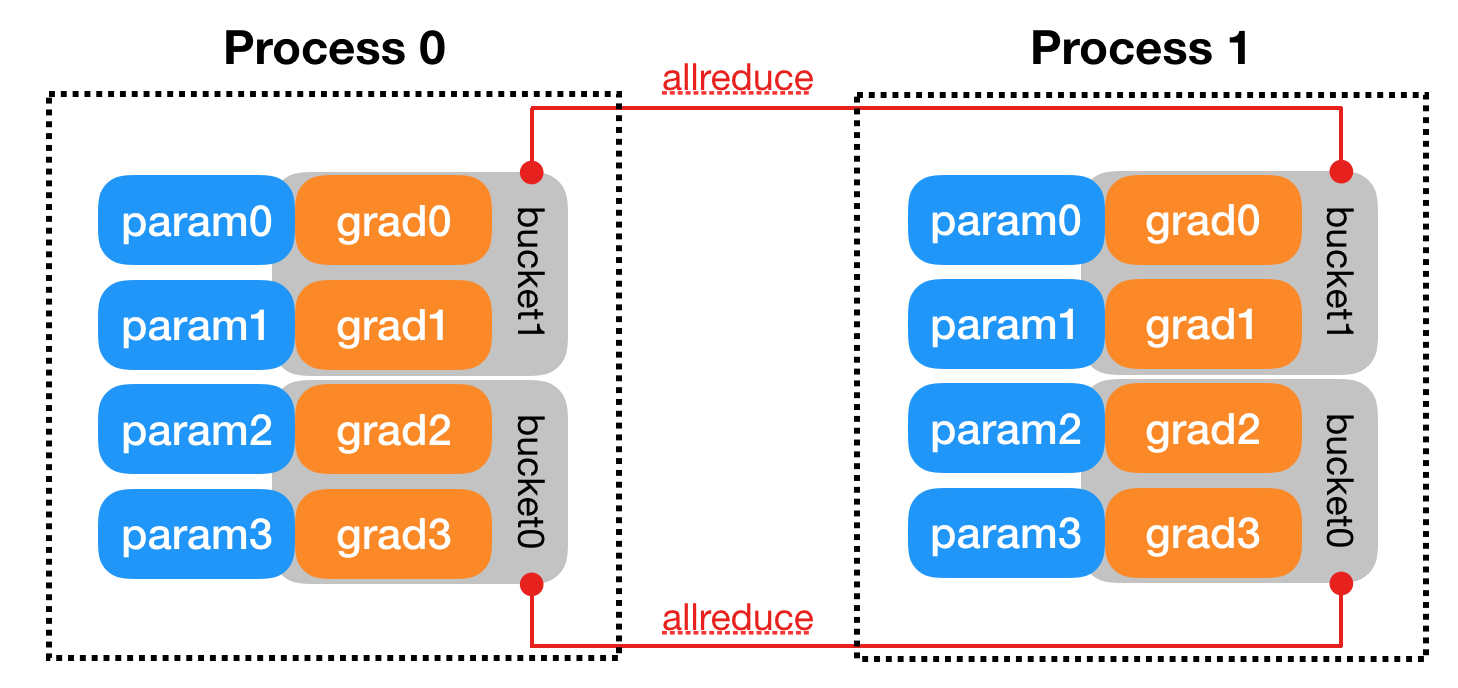
梯度分桶的两个要点
- DDP的Bucket中的参数是按model.parameters()倒序插入的,在实际执行中$bucket_{i+1}$ 必须在$bucket_i$ 完成后才能进行,在文章中提到这是工程上的近似,因为模型梯度参数梯度更新的顺序不一定完全和模型参数的顺序一致,但在大多数情况这样方法是适用且高效的。所以,在创建model的时候,请务必把先进行计算的parameter注册在前面,后计算的在后面。不然,reducer会卡在某一个bucket等待,使训练时间延长,出现图(a)中的情况,进程2的$g_2$参数的梯度在$g_3,g_4$后更新导致进程2的第二个Bucket迟迟无法进行ALLReduce操作。
- 因为pytorch是完全的动态图机制,每次训练中不是所有子图都会参与训练,在模型中部分子图被冻结,不参与梯度更新时,在创建ddp Model时需要把
find_unused_parameter设置为true,否则一个Bucket中有一个参数的梯度没有ready就不会进行Allreduce,如图(b)。find_unused_parameter为true时在每次前向传播后会搜索所有没有参与梯度更新的参数并把它们的状态设置为ready。

hook机制
前文提到pytorch DDP设计者在设计API时希望DDP的功能不会对原有训练流程有影响,即非侵入式的API,这利用了实现Pytorch中的hook实现。
用形象的话讲,hook提供了这么一种机制:程序提供hook接口,用户可以写一个hook函数,然后钩在hook接口,即程序的主体上从而可以插入到中间执行。DDP使用hook技术把自己的逻辑插入到module的训练过程中去。
parameter在反向梯度计算结束后提供了一个hook接口。DDP把Ring-Reduce的代码写成一个hook函数,插入到这里。每次parameter的反向梯度计算结束后,程序就会调用这个hook函数,从而开启Ring-Reduce流程。
DDP代码和执行流程
代码
下面是实现DDP的一段最简单的代码Demo,对原有训练流程没有任何改动,只需额外的两行代码dist.init_process_group("gloo", rank=rank, world_size=world_size)和ddp_model = DDP(model, device_ids=[rank])
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# 创建进程组
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# 创建模型
model = nn.Linear(10, 10).to(rank)
# 创建DDP模型
ddp_model = DDP(model, device_ids=[rank])
# 定义损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# 前向传播
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# 反向传播
loss_fn(outputs, labels).backward()
# 更新参数
optimizer.step()
DDP执行流程
- 准备阶段
- 环境初始化
- 在各张卡上初始化进程并建立进程之间的通信
- 对应代码:init_process_group
- 模型广播
- 将模型parameter,buffer广播到各节点
- 对应代码:model = DDP(model)
- 初始化Bucket
- 将模型的参数倒序分配到各个桶中(为什么必须倒序后面会讲)
- 对应代码:model = DDP(model)
- 创建管理器reducer,给每个parameter注册梯度平均的hook。
- 环境初始化
- 训练阶段
- 采样数据(for data, label in dataloader)
+从dataloader得到一个batch的数据,用于当前计算。 - 前向传播(output = model(data))
- 同步各进程状态(parameter和buffer)
- 前向计传播
- 当DDP参数find_unused_parameter为true时,其会在forward结束时,启动一个回溯,标记出所有没被用到的parameter,提前把这些设定为ready。
- 计算梯度(loss.backward())
- reducer外面:各个进程各自开始反向地计算梯度。
- reducer外面:当某个parameter的梯度计算好了的时候,其之前注册的grad hook就会被触发,在reducer里把这个parameter的状态标记为ready。
- reducer里面:当某个bucket的所有parameter都是ready状态时,reducer会开始对这个bucket的所有parameter都开始一个异步的all-reduce梯度平均操作。
- reducer里面:当所有bucket的梯度平均都结束后,reducer才会把得到的平均grad结果正式写入到parameter.grad里面。
- 优化器optimizer应用gradient,更新参数(optimizer.step())。
- 采样数据(for data, label in dataloader)
梯度累计
对于DDP的ALLreduce,文章中提到进一步的改进方法,使用梯度累计来进一步减少通信次数,DDP的梯度同步在loss.backward()阶段进行,Pytorch提供了model.no_sync()接口,可以使反向传播取消梯度同步,这样我们可以选择K次迭代进行一次梯度同步,当然K不建议取的过大,代码如下。
model = DDP(model)
for 每次梯度累加循环
optimizer.zero_grad()
# 前accumulation_step-1个step,不进行梯度同步,累积梯度。
for _ in range(K-1)::
with model.no_sync():
prediction = model(data)
loss = loss_fn(prediction, label) / K
loss.backward() # 积累梯度,不应用梯度改变
# 第K个step,进行梯度同步
prediction = model(data)
loss = loss_fn(prediction, label) / K
loss.backward() # 积累梯度,不应用梯度改变
optimizer.step()
DDP未来可能的改进方式
对于当前基于Bucket的DDP实现,文章提到了下面三种可能改进的方式
梯度顺序预测
目前DDP的模型parameter和Bucket的参数的map映射关系是直接将模型的参数按model.parameter() reverse后将Bucket一一填满,每个Bucket的容量默认为25MB个参数,,所以实际执行时可能出现阻塞现象,所以可以考虑更加智能的parameter到Bucket的映射算法
layer dropping
在网络采用dropout时每次前向传播都会构建一个新的计算图,DDP同样也支持Dropout,但是由于parameter到bucket的映射是固定的,虽然没次前向传播后会把这些dropout的参数设定为ready,但是这也带来了额外的内存开销。解决这样的方法一种是修改parameter到bucket的映射,另一种是将一个layer映射到bucket,每次更新直接跳过一个bucket。
梯度压缩
DDP的另一种改进是压缩梯度,将FP64,FP32,压缩为更低精度的IN8,所以可以考虑使用自适应的梯度压缩策略。
