Mixed Precision Training
Mixed Precision Training
2018年ICLR的文章,来自Nvidia,现在流行的混合精度训练的方案基本基于这篇文章,Nvidia针对Pytorch开发了Extension Apex,可以完美地在Pytorch中进行混合精度训练,在Pytorch 1.6的版本中,这个特性被Pytorch官方merge到Pytorch中,Pytorch原生支持了amp(自动混合精度训练),解决了apex经常和Pytorch版本不兼容的问题
Absract
提升神经网络的规模通常会提高模型预测的准确率,但同时也会有更高的内存和计算要求。这篇文章主要介绍了在不降低模型的准确性并不修改超参数的条件下,使用半精度浮点数训练深度神经网络的方法。半精度训练可以将模型在GPU上的内存需求减半,并且可以加快运算速度。权重、激活和梯度都以IEEE半精度格式存储。由于这种格式的范围比单精度的要窄,所以我们提出了三种技术来防止关键信息的丢失。首先,我们建议维护一个单精度的权重副本,在每个优化器步骤后积累每个优化器步骤后的梯度(这个副本对于正向和反向传播来说被四舍五入为半精度)。第二,我们提出损失缩放,以保留小幅度的梯度值。第三,我们使用半精度计算,累积成单精度输出,在存储到内存之前将其转换为半精度。我们证明了所提出的方法在各种任务和现代大规模(超过1亿个参数)的模型架构中都能发挥作用。
论文解决什么问题?
大模型需要更多的计算资源和内存开销,对网络参数进行低精度的表示和计算是解决上述问题对一个重要方法,网络对训练和推理速度取决于以下三个方面:
- 计算带宽(arithmetic bandwidth)
- 内存带宽 (memory bandwidth
- 通信延迟 (communication latency)
低精度低低参数表示可以很好地降低前两者地开销,现代地机器学习系统使用单精度(FP32)的格式,这篇文章希望在保持模型准确率不变的情况下使用半精度(FP16)进行训练
并提出了三种防止模型精度损失的技术:
- 为所有参数保存一个FP32的主副本,
- 梯度缩放(loss scaling)。
- 使用FP16运算并将结果累加到FP32到内存中。
文章对CNN和RNN结构,训练了用于分类、回归和生成任务,应用包括图像分类、图像
生成、物体检测、语言建模、机器翻译和语音识别,都取得了不错的效果。
论文解决问题到方法
accumulating FP16 products into FP32(使用FP16运算并将结果累加到FP32到内存中)
NVIDIA Volta GPU架构引入了Tensor Core指令,它将半精度矩阵相乘,将结果累加到单精度或半精度输出中。论文指出累积到单一精度对于获得良好的训练结果至关重要。在写入存储器之前,累计值将转换为半精度。cuDNN和CUBLAS库提供了各种依赖Tensor Cores进行算术运算的函数。
loss scaling(梯度缩放)
训练 DNN 时会遇到四种类型的张量:激活、激活梯度、权重和权重梯度。根据经验,激活、权重和权重梯度落在以半精度表示的值幅度范围内。然而,对于一些网络,小幅度的激活梯度低于半精度范围。激活梯度不使用大多数半精度范围,它们往往是幅度低于 1 的小值。因此,我们可以通过将激活梯度乘以比例因子S将激活梯度“转移”到 FP16 可表示的范围内。确保梯度落在半精度可表示的范围内的一种非常有效的方法是将训练损失乘以比例因子。这仅添加了一个乘法,并且通过链式法则,它确保所有梯度都按比例放大(或向上移动)而无需额外成本。损失缩放确保恢复丢失为零的相关梯度值。 在权重更新之前,权重梯度需要按相同的因子S缩小。
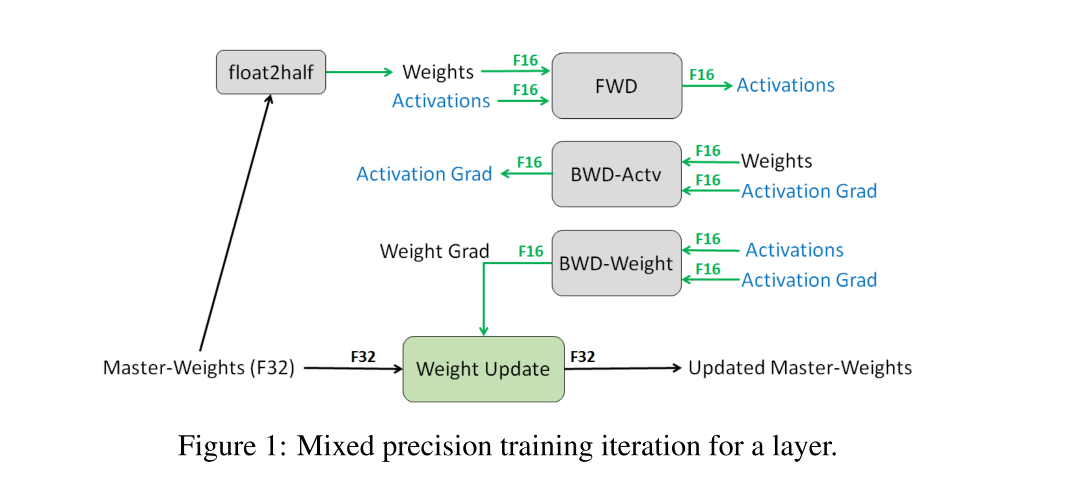
FP32 Master Copy of Weights(保存一份FP32的权重副本)
保存一个单精度浮点的权值备份。在训练过程中舍入到半精度,FP16在硬件实现中更快。(加速训练、减少硬件开销、存储的参数量增加了50%,但是由于减少了过程中的activation,所以总体来说还是减少了memory的消耗)。
假如单纯的使用FP16训练,精度降低了80%,所以要使用32位量化训练,但是参数更新过程使用16位。过程如下图所示。