流水线并行论文总结
基础概念
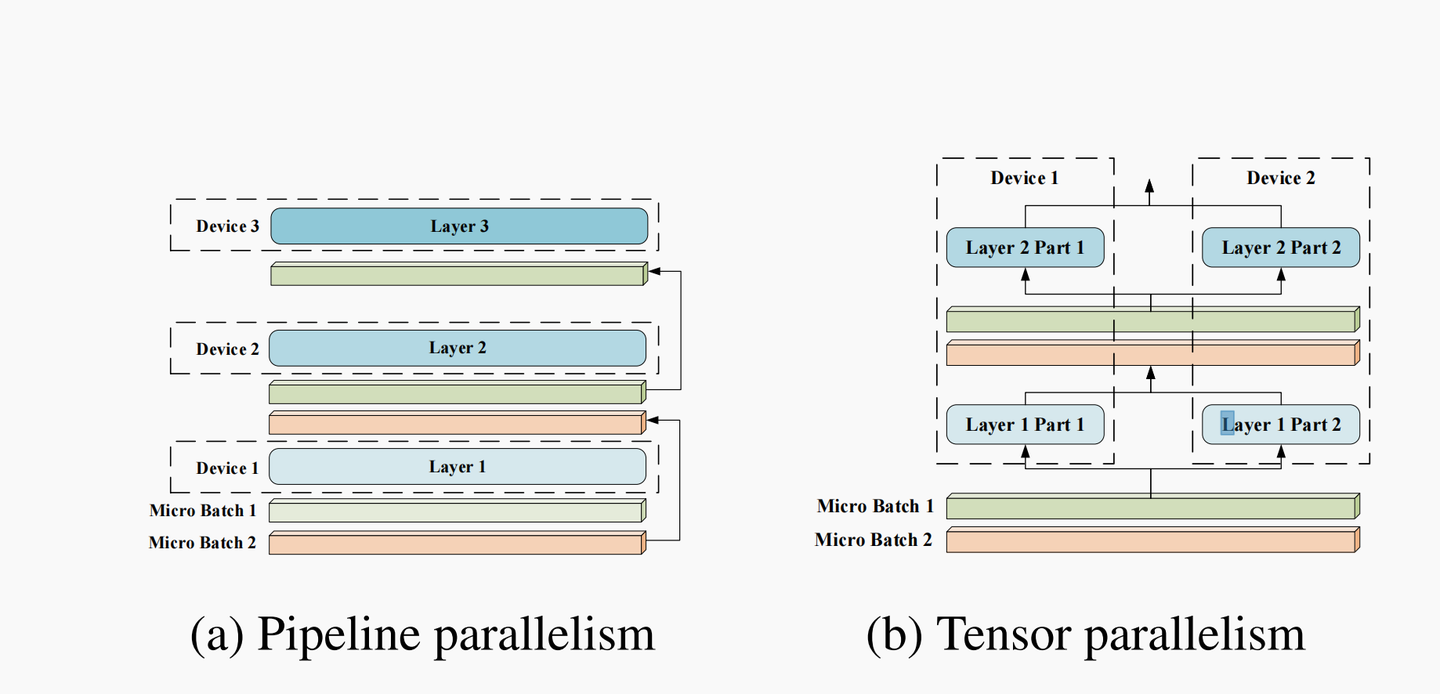
模型并行 模型并行分为两种:流水线并行和张量并行,也可以称作算子内并行(intra-operator parallelism)和算子间并行(interoperator parallelism)(Alpa 中的叫法)
- 流水线并行(pipeline model parallel)
- 把模型不同的层放到不同设备之上,比如前面几层放到一个设备之上,中间几层放到另外一个设备上,最后几层放到第三个设备之上。
- 张量并行
- 层内分割,把某一个层做切分,放置到不同设备之上,也可以理解为把矩阵运算分配到不同的设备之上,比如把某个矩阵乘法切分成为多个矩阵乘法放到不同设备之上。
添加图片注释,不超过 140 字(可选)
通讯开销对比
- 张量并行:
- 通信发生在每层的前向传播和后向传播过程之中,通信类型是all-reduce,不但单次通信数据量大,并且通信频繁。
- 通常适合节点内使用, 通过 NVLink 来进行加速
- 流水线并行
- 通信在流水线阶段相邻的切分点之上,通信类型是P2P通信,单次通信数据量较少但是比较频繁,而且因为流水线的特点,会产生GPU空闲时间,这里称为流水线气泡(Bubble)。
- 通常更适合节点间使用,一般通过 Infiniband 交换机进行连接。
流水并行(pipeline parallelism)的核心问题
- 流水线并行的一个挑战是确保各个阶段在计算工作量方面得到适当平衡。 如果一个阶段的执行时间比其他阶段长得多,它可能会造成瓶颈,从而减慢整个训练的速度。 为了解决这个问题,可能需要调整每个阶段处理的数据批次的大小或实施动态负载平衡技术。
- 流水线并行的另一个挑战是管理不同处理单元之间的通信。 在某些情况下,可能需要在不同阶段之间传输数据或中间结果,这样会引入通信开销和延迟。 为了解决这个问题,可能需要使用高效的数据传输协议或重叠计算和通信以最小化通信延迟的影响。 基础流水并行框架
添加图片注释,不超过 140 字(可选)
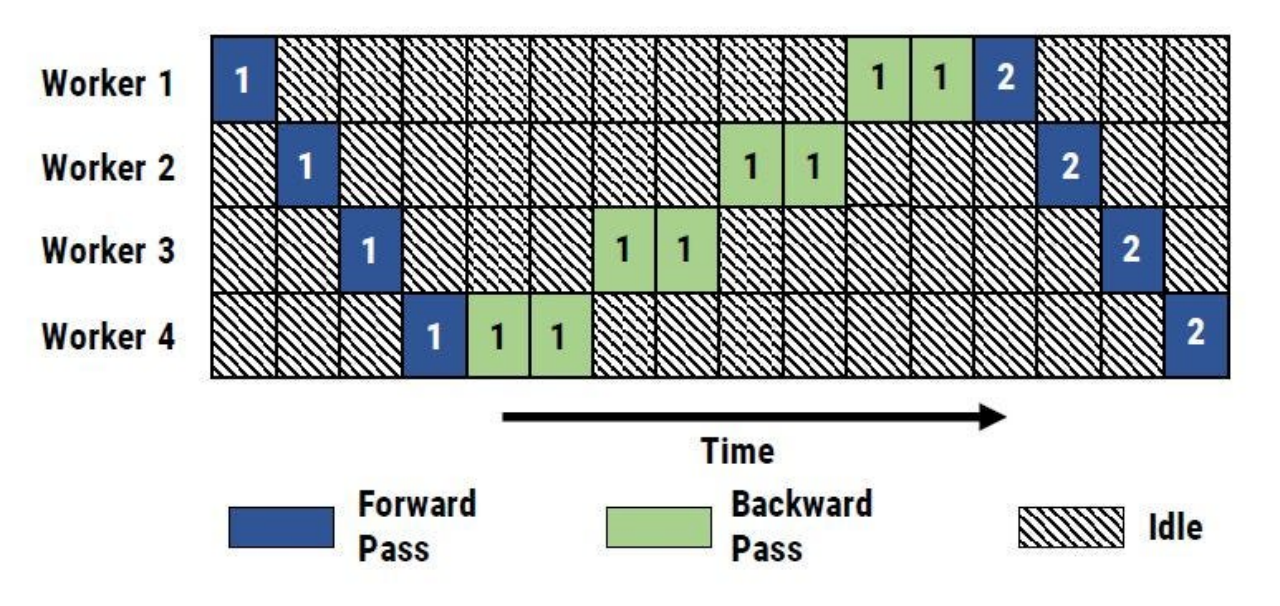
- 计算资源利用率低:在任何一个时间,只有一个计算设备在执行计算,而其他的计算设备都处于空闲状态,每个计算设备在忽略通信时间的情况下,N个计算设备的情况下, 总的时间利用率只有 1/N, 如果增加更多的计算设备,那么每个设备的利用率会更低。因此需要对正在空闲的计算设备指定任务以此增加计算设备的利用率。这种下游设备需要长期持续处于空闲状态,等待上游设备的计算完成,才可以开始计算的现象被称为Bubble。
- 计算和通信顺序执行:当在不同设备之间传输前向计算的中间结果和反向传播时的梯度时,没有任何的计算设备在计算,这也导致了资源的浪费,因此计算和通信需要仔细的设计来增加设备的使用效率。
- 如何划分层:由于需要将模型的一系列层划分到不同设备之间,不同的划分策略往往会影响计算的性能,因此如何对模型进行划分也会对性能产生重要的影响。
GEMS (SC 20)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
假设一个网络有L层,每一层L(i)包含对应的前向计算函数和一系列参数。GPipe对每层的计算有个成本计算函数, 给定划分的数量K,GPipe会根据成本计算函数将L层网络会被分成K组,每组中包含一定连续的层数,相邻的两组设备之间的通信操作也会自动设置好。在前向计算的过程中,GPipe会将batch 划分成M份相等的micro-batch,这样M份micro-batch就可以在M个计算设备之间进行流水。在反向传播计算期间,每个micro-batch的梯度是基于用于前向传播计算的模型参数计算的。 在最后对于每个micro-batch,将来自所有 M 个micro-batch的梯度累加起来并应用于更新所有计算设备的模型参数。

添加图片注释,不超过 140 字(可选)
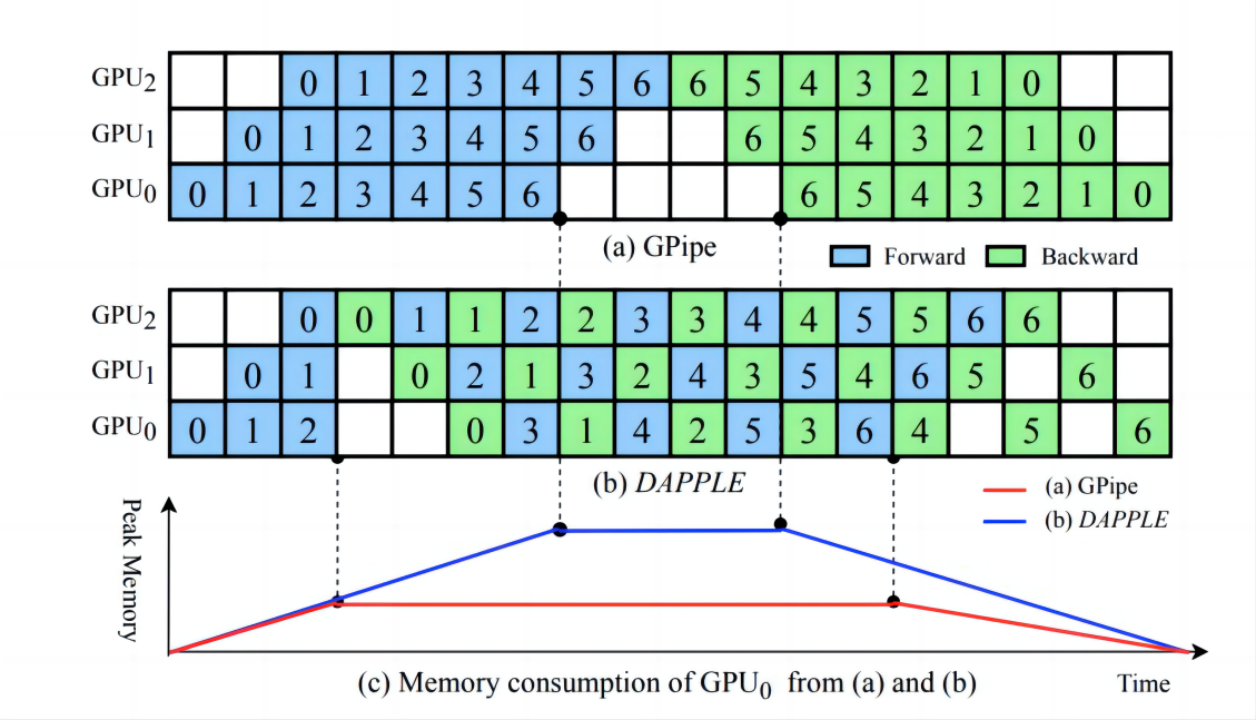
DAPPLE 是一个同步分布式训练框架,它结合了大型 DNN 模型的数据并行性和流水并行性。主要思想是更早地安排反向传播任务从而释放用于存储相应前向传播任务产生的激活的内存。DAPPLE相较于GPipe改变了排布,没有减小bubble rate,但是减小了activation的占用,对比GPipe的调度机制。 DAPPLE不是一次性执行所有 M 个mini-batch,而是在开始时执行K 个mini-batch (K < M) 从而开始释放内存压力,同时到达内存使用的最高点。其次,严格安排一个mini-batch的前向传播后,紧接着就是一个反向传播,以保证反向传播可以提前执行。 下图 显示了GPipe 和 DAPPLE 中的内存消耗如何随时间变化。 在前K个min-batch, DAPPLE和 GPiped的内存消耗相同,直到第 K 个mini-batch, 然后由于更早的反向传播而DAPPLE达到内存使用的最大值。具体来说,严格控制执行前向传播和反向传播的顺序,由前向传播执行一个mini-batch之后,activation占用的内存由后向传播执行所释放。相比之下,GPipe 的峰值内存在K个mini-batch之后持续增长没有提早释放。 此外,DAPPLE 并不牺牲流水线训练效率。
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
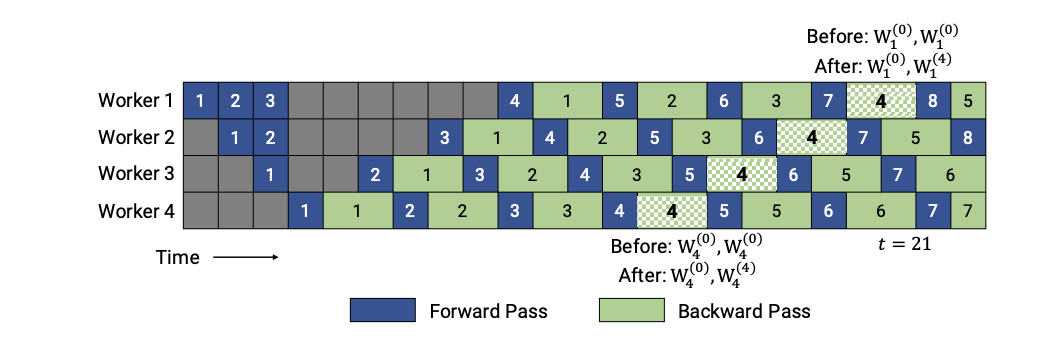
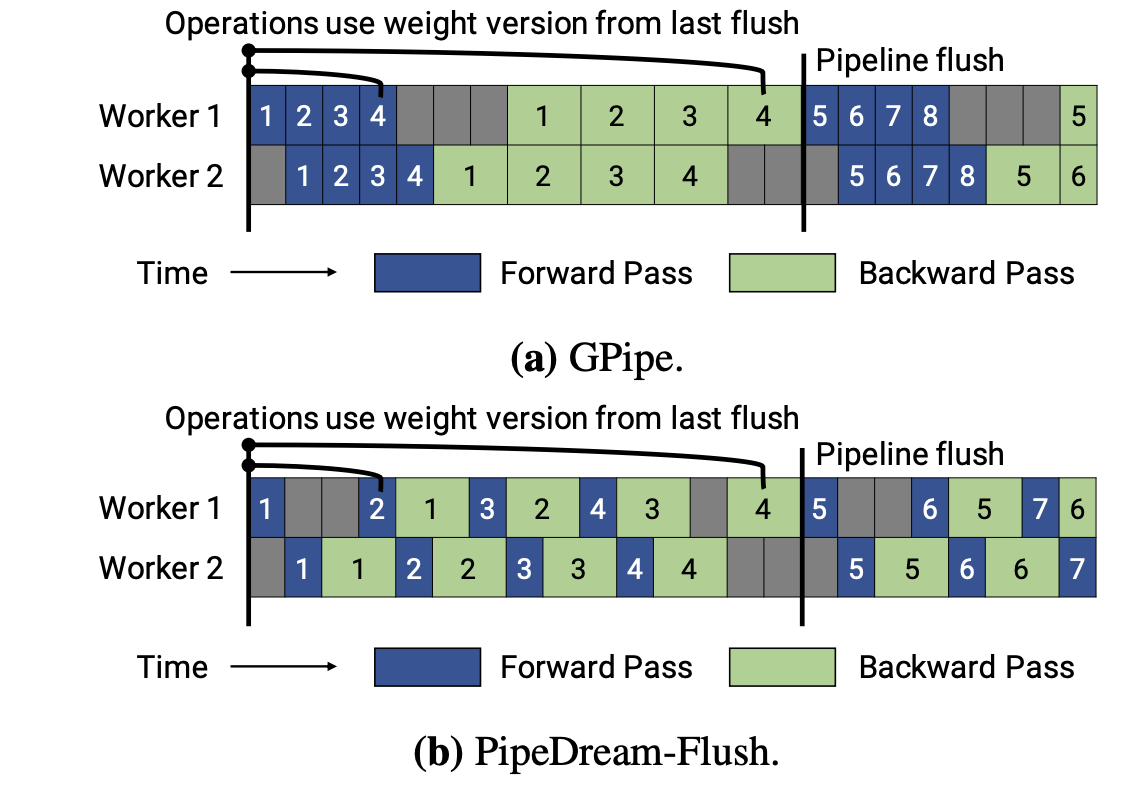
PipeDream 采用1F1B(One Forward pass followed by One Backward pass)模式,一种前向计算和反向计算交叉进行的方式。在 1F1B 模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。 PipeDream 和 GPipe 之间的区别很明显:PipeDream 应用异步向后更新,而 GPipe 应用同步向后更新。 PipeDream-Flush and PipeDream-2BW(ICML21) PipeDream 使用权重存储方案来确保相同输入的前向和后向传播中使用相同的权重版本。 在最坏的情况下,隐藏的权重版本总数为 d,其中, d 是流水线深度,这对于大模型来说太高了。 而且使用 PipeDream 默认的权重更新语义,每个阶段(state)的权重更新都有不同的延迟项;同时,流水线内不会执行累积。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
Virtual pipeline Megatron-LM
添加图片注释,不超过 140 字(可选)
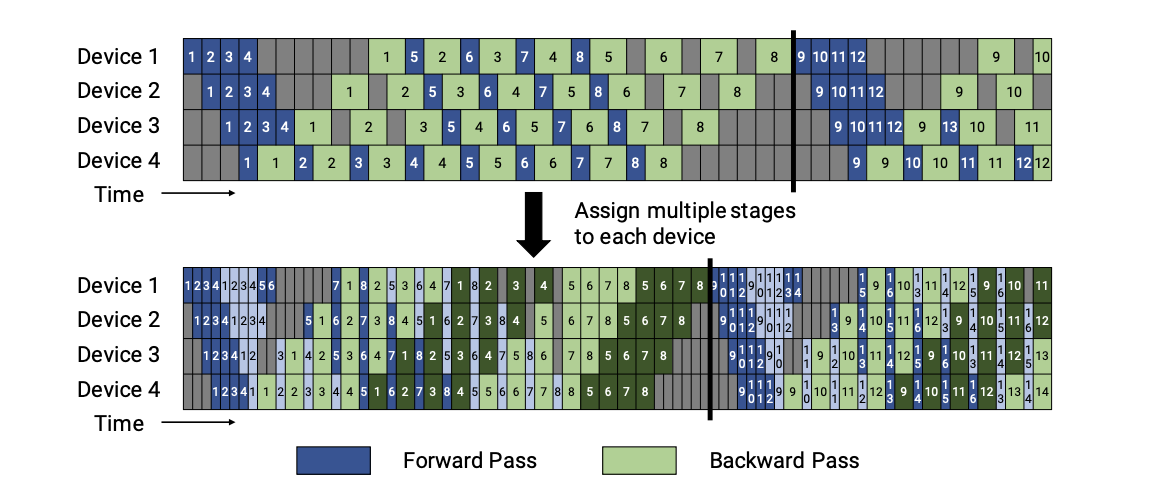
非交错式 schedule 可分为三个阶段。第一阶段是热身阶段,处理器进行不同数量的前向计算。在接下来的阶段,处理器进行一次前向计算,然后是一次后向计算。处理器将在最后一个阶段完成后向计算。这种模式比 GPipe 更节省内存。然而,它需要和 GPipe 一样的时间来完成一轮计算。 交错 Schedule要求microbatches的数量是流水线阶段的整数倍。在这个 schedule 中,每个设备可以对多个层的子集(称为模型块)进行计算,而不是一个连续层的集合。具体来看,之前设备1拥有层1-4,设备2拥有层5-8,以此类推;但现在设备1有层1,2,9,10,设备2有层3,4,11,12,以此类推。 在该模式下,流水线上的每个设备都被分配到多个流水线阶段,每个流水线阶段的计算量较少。 Virtual pipeline 降低了bubble,提升了通信次数。 Chimera (SC’21)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
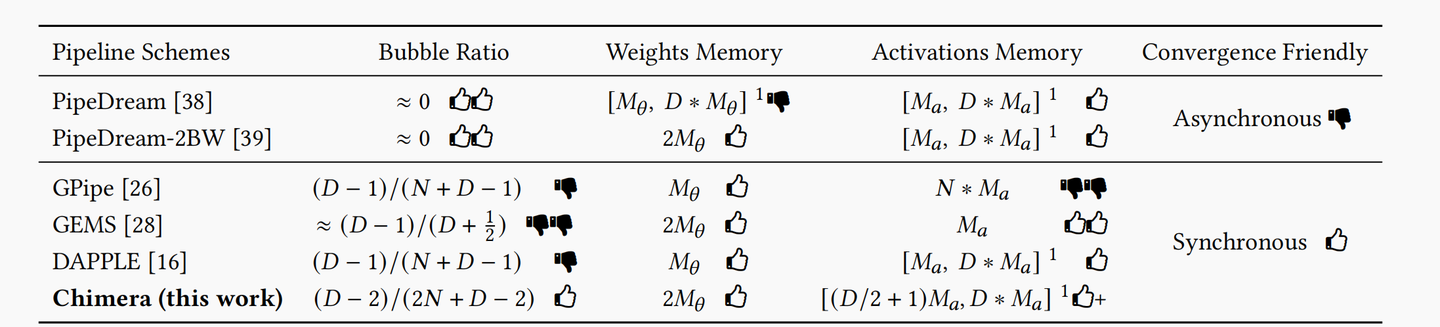
Chimera 使用双流水线进行交叉排布,极大地减小了的bubble rate,但是增加了一倍weight的显存占用
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
Alpa同时考虑PP+TP+DP,Alpa 将并行性视为两个层次级别:算子内并行(intra-operator parallelism)和算子间并行(interoperator parallelism。Alpa使用整数线性规划(ILP)完成算子间并行规划,动态规划算法来完成算子外并行规划。 常见分布式训练框架Pipeline parallelism方案
- 在 PyTorch 中,采用的是GPipe方案。使用的是F-then-B调度策略。
- 在 DeepSpeed 中,采用的是PipeDream-Flush,使用的是非交错式1F1B调度策略
- 在 Megatron-LM 中,基于PipeDream-Flush进行了改进,提供了一种交错式1F1B方案。
- 在 Colossal-AI 中,基于Megatron-LM的交错式1F1B方案,提供了非交错(PipelineSchedule) 和交错(InterleavedPipelineSchedule) 调度策略。
Reference
- GEMS:https://ieeexplore.ieee.org/document/9355254
- GPipe :https://arxiv.org/pdf/1811.06965.pdf
- PipeDream:https://arxiv.org/abs/1806.03377
- PipeDream-Flush and PipeDream-2BW:https://arxiv.org/abs/2006.09503
- Virtual pipeline Megatron-LM: https://arxiv.org/abs/2104.04473
- DAPPLE :https://arxiv.org/abs/2007.01045
- Chimera :https://arxiv.org/abs/2107.06925
- Alpa:https://arxiv.org/abs/2201.12023
