RNN
循环序列模型
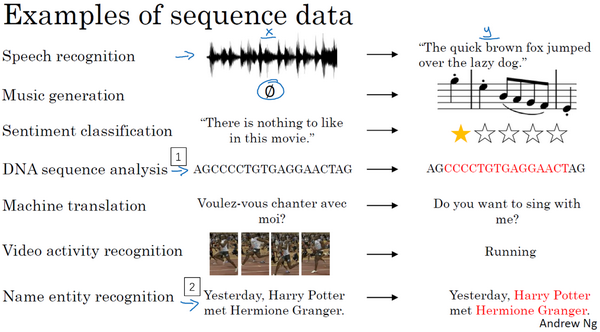
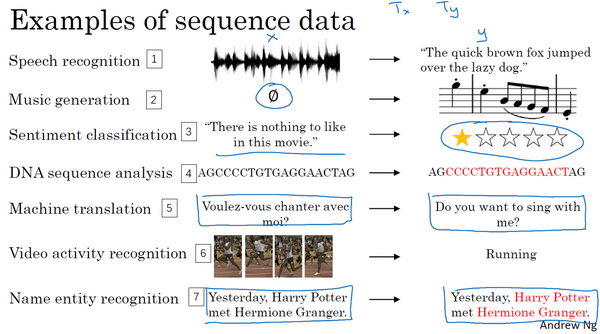
为什么选择序列模型
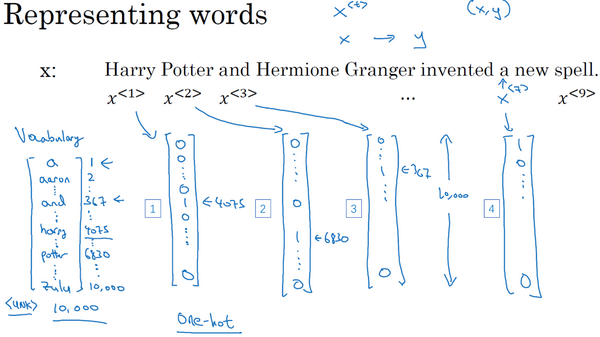
数学符号
- 输入$x^{
}$ - 输出$y^{
}$ - 序列长度$T_x$
- 词向量one-hot编码
RNN模型
用普通神经网络的问题
- 输出和输入维度不对应
- 序列前后不存在联系
解决,引入RNN
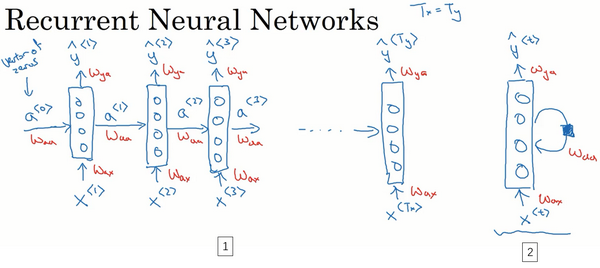
更一般情况
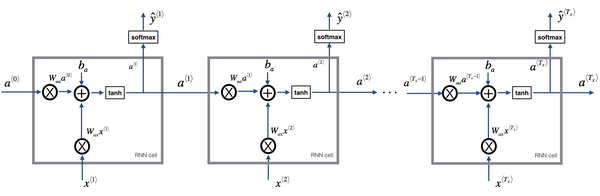
进一步化简
前向传播
RNN常用激活函数
- tanh
- ReLU
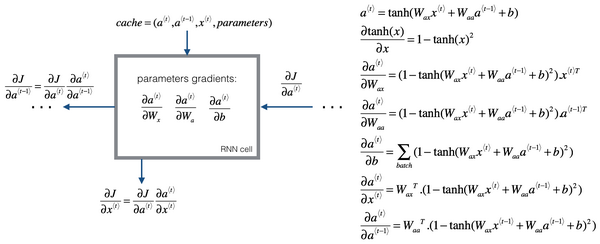
通过时间的反向传播
单个单元Loss Function
Loss function
RNN反向传播计算
不同类型的RNN结构
多对一
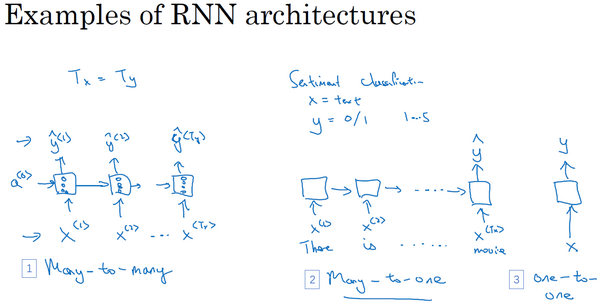
一对一
一对多
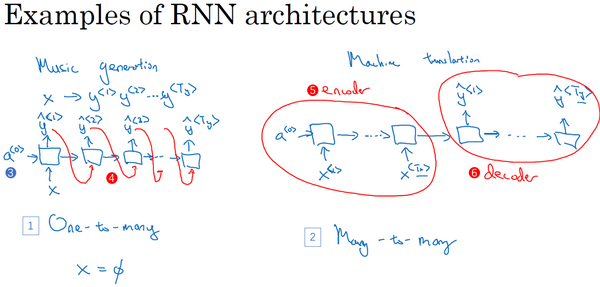
语言模型和序列生成
语言模型所做的就是,它会告诉你某个特定的句子它出现的概率是多少
语言模型建立步骤
- 获取大量数据集
- 句子标记化
- 构建RNN
RNN梯度消失的问题
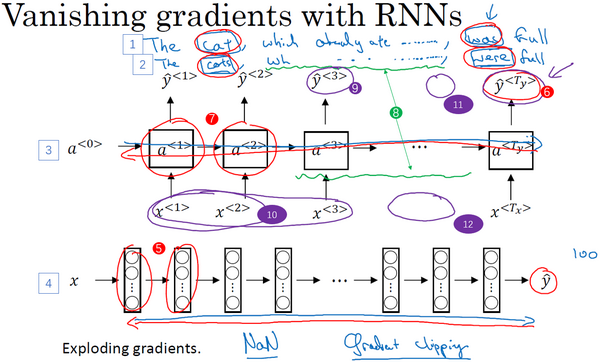
RNN存在问题
- 缺乏长期记忆,如cat和were
- 梯度爆炸
如何解决?
- GRU
- LSTM
GRU
cell单元
GRU简化模型
相关性
LSTM
LSTM模型图
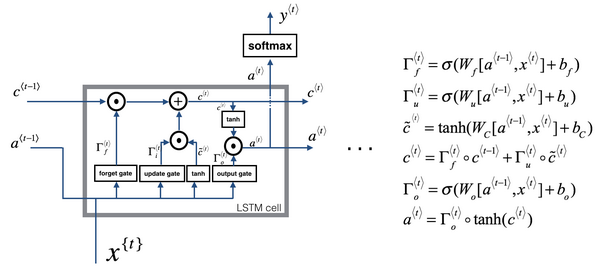
LSTM单元
- 更新门
- 遗忘门
- 输出门
- 激活函数
- 相关性门
LSTM的前向传播
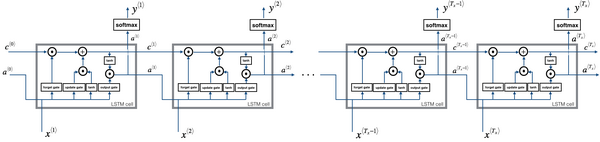
LSTM反向传播
门求偏导
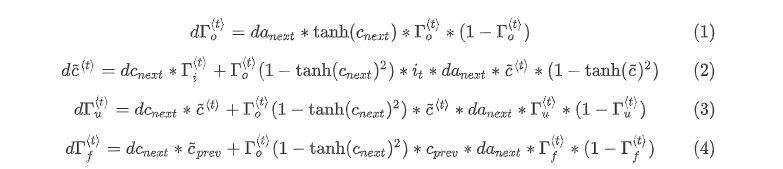
参数求偏导
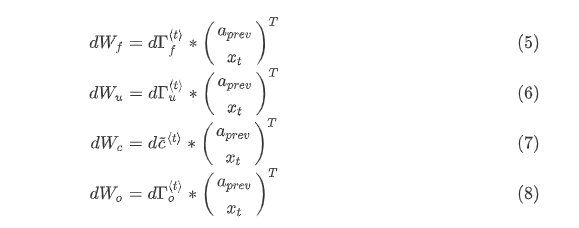
参数更新
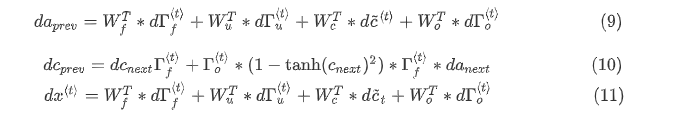
双向RNN
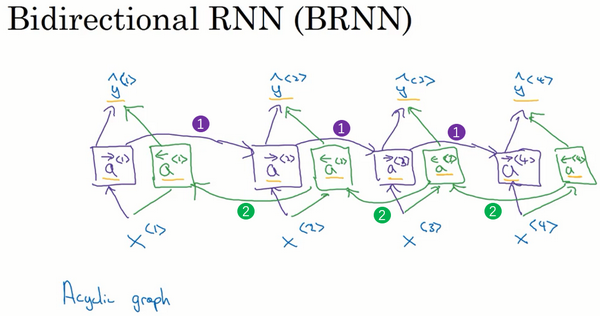
深层RNN
自然语言处理和词嵌入
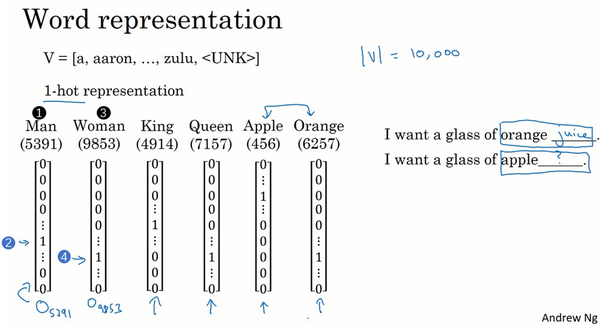
词汇表征
one-hot编码的缺点
- 每个词孤立,泛化能力不强
- 数据量太大
如何改进?
应用特征向量
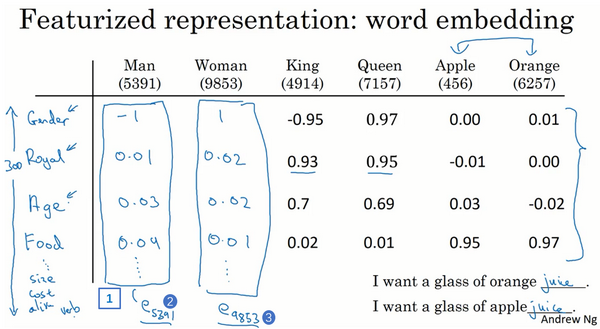
t-SNE 算法
将一维词向量转化为二维可视化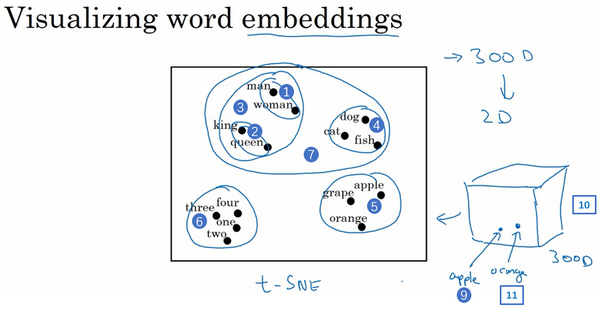
使用词嵌入
词嵌入做迁移学习的方法
- 先从大量的文本集中学习词嵌入。一个非常大的文本集,或者下载预训练好的词嵌入模型
用这些词嵌入模型把它迁移到新的只有少量标注训练集的任务中,比如说用这个300维的词嵌入来表示的单词。这样做的一个好处就是可以用更低维度的特征向量代替原来的10000维的one-hot向量,现在你可以用一个300维更加紧凑的向量。尽管one-hot向量很快计算,而学到的用于词嵌入的300维的向量会更加紧凑。
在你的任务上训练模型时,在你的命名实体识别任务上,只有少量的标记数据集上,你可以自己选择要不要继续微调,用新的数据调整词嵌入。实际中,只有这个第二步中有很大的数据集你才会这样做,如果你标记的数据集不是很大,通常我不会在微调词嵌入上费力气。
词嵌入的特性
- 类比推理
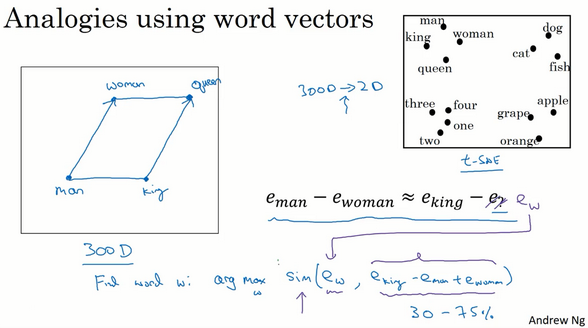
如何反映相似度?
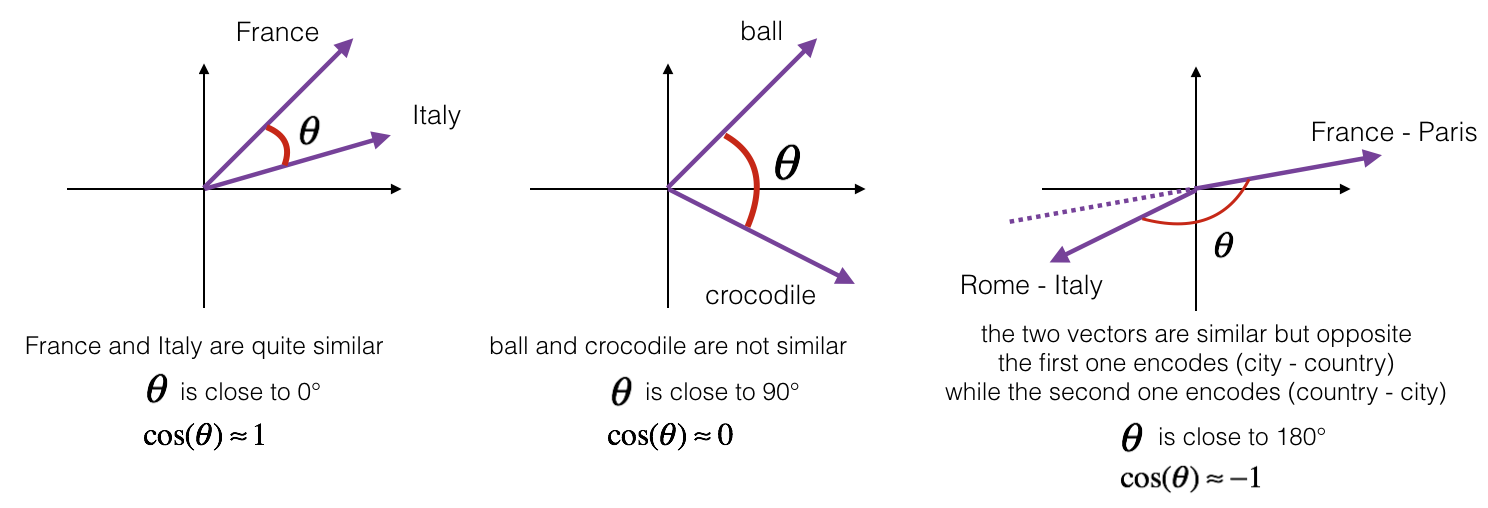
余弦相似度
嵌入矩阵
学习词嵌入其实是学习一个嵌入矩阵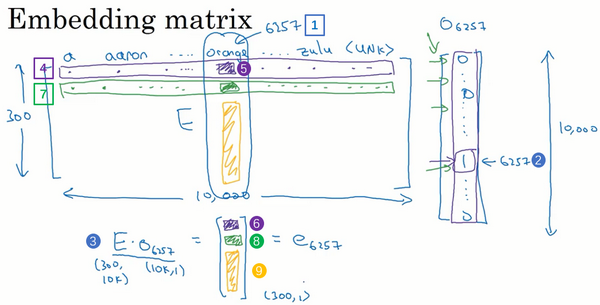
学习词嵌入
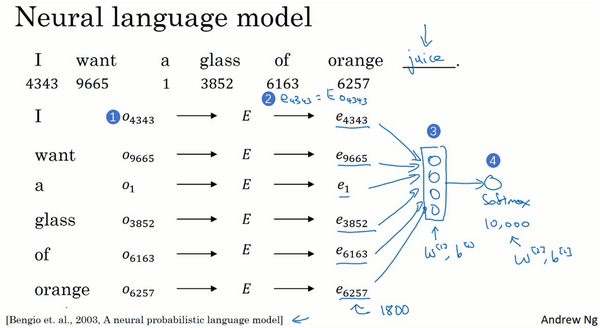
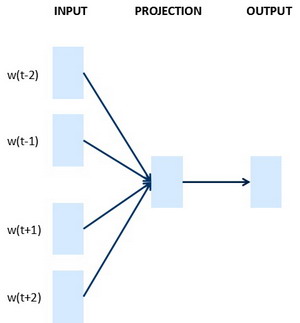
skip-gram
输入:预测的词汇前n个单词,上下文
输出:softmax的rank
- 随机生成一个嵌入矩阵
- 学习嵌入矩阵参数
Word2Vec
学习映射关系
- 随机选择目标单词上下文的另一个单词
- 输入one-hot向量
- 监督学习
softmax:
存在问题
softmax运算量太大
解决方法
- 分级
- 负采样
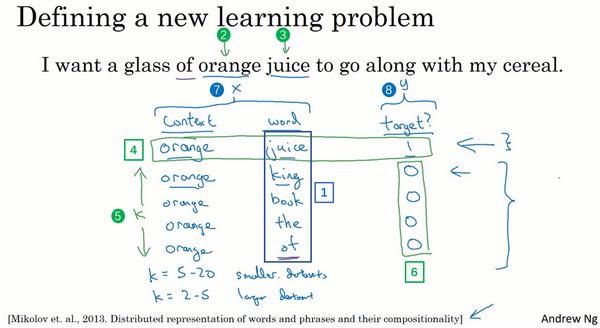
CBOM和skip-gram
负采样(Negative Sampling)
- 给定一对单词和target
- 使用逻辑回归
- 输入one-hot向量
- 传递给嵌入矩阵
- 得到10000个逻辑回归问题
- 只选取其中K个进行训练
- 转化为K个二分类问题
Glove(global vectors for word represengtation)
- $x_{ij}$:单词i和单词j在上下文出现的次数

情感分类


词嵌入除偏(Debiasing Word Embeddings)
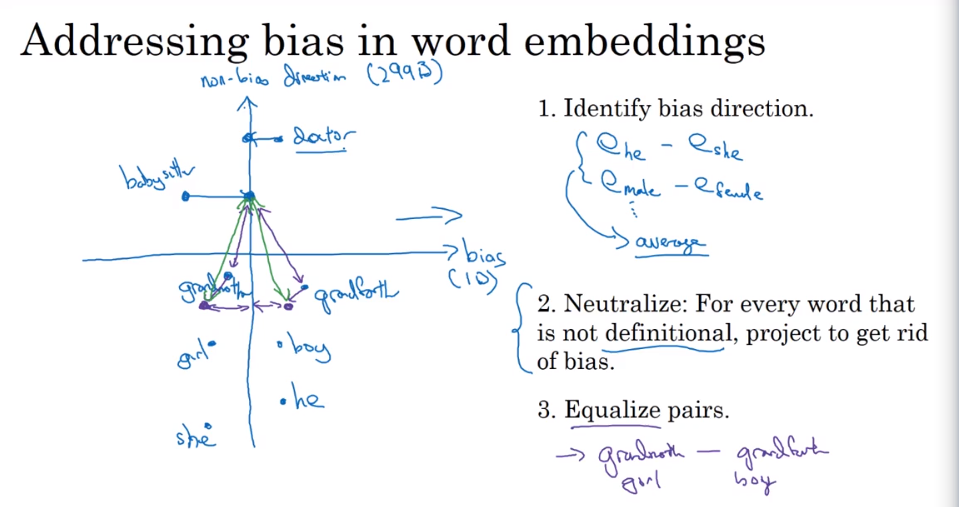
- 求平均
- 中和
- 均衡步
序列模型和注意力机制(Sequence models & Attention mechanism
基础模型
应用
- 机器翻译
- 语言识别
机器翻译
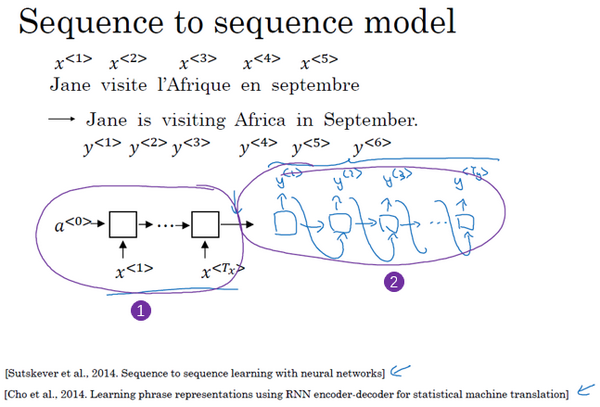
- 输入法语,输出英语
- 网络结构:LSTM或GR
图片描述
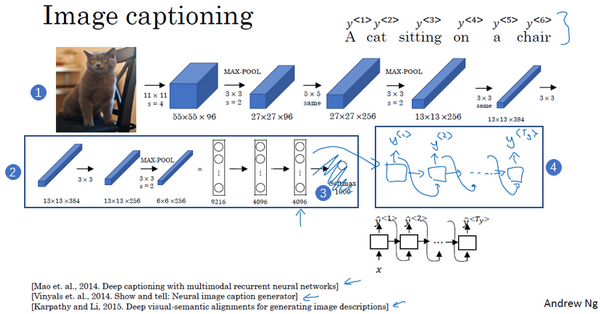
- 输入图片
- 进入卷积神经网络如AlexNet
- 把softmax单元更换为RNN结构
- 输出描述图片的序列
选择最可能的句子(Picking the most likely sentence)
语言模型和机器翻译模型的区别
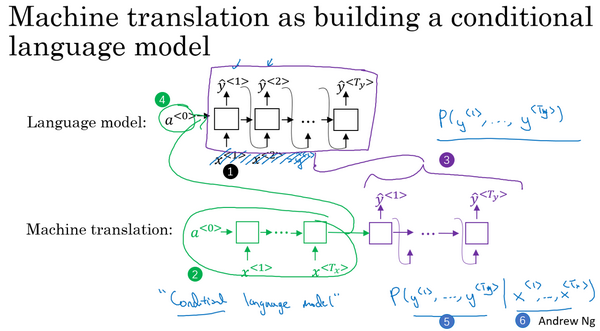
- 语言模型以零向量开始,翻译模型从句子开始
- 翻译模型为条件语言模型
最大化以下式子
为什么不用Greed search
- 我们需要一次性输出整个句子而不是一个单词
- 运算量太大
贪心搜索是一种来自计算机科学的算法,生成第一个词的分布以后,它将会根据你的条件语言模型挑选出最有可能的第一个词进入你的机器翻译模型中,在挑选出第一个词之后它将会继续挑选出最有可能的第二个词,然后继续挑选第三个最有可能的词,这种算法就叫做贪心搜索。
Beam Search
- beam width$B=3$,选择softmax前三个最大值
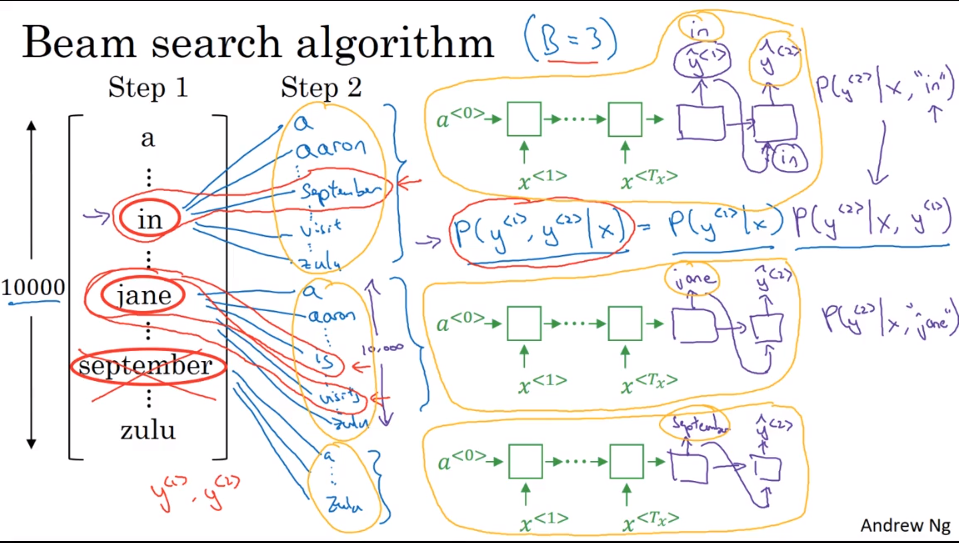
- 输入句子,如“Jane visite l’Afrique en Septembre”
- 选择第一个单词,保留前三的可能性
- 确认单词对的最大可能性
- 继续重复该步骤
Beam search 改进
Length normalization
加入log函数
加入参数$\alpha$
how to choose Beam width B
- B=1贪心算法
- B过大,计算量大,效果没有显著提升
Beam search 误差分析
- $P(y^*|x)>P(\hat{y}|x)$束搜索算法出错
- $P(y^*|x)<P(\hat{y}|x)$RNN模型出错
RNN实际上是一个编码器合解码器
如何评价一个翻译系统的好坏
- 与人工翻译进行对比
- 观察输出是否在参考中
- 每个单词加入计分上限
Blue score
考虑词组得分

注意力模型(Attention Model)
长句子的问题
blue score降低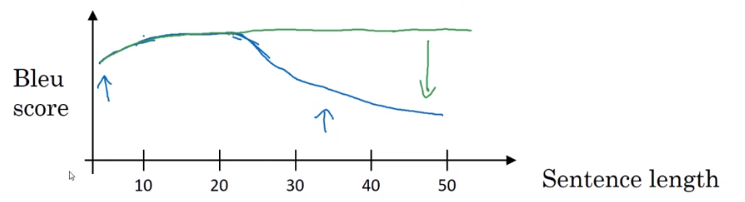
注意力权重$\alpha<t,t’>$
第t个输出单词对应第t‘个输入单词的权重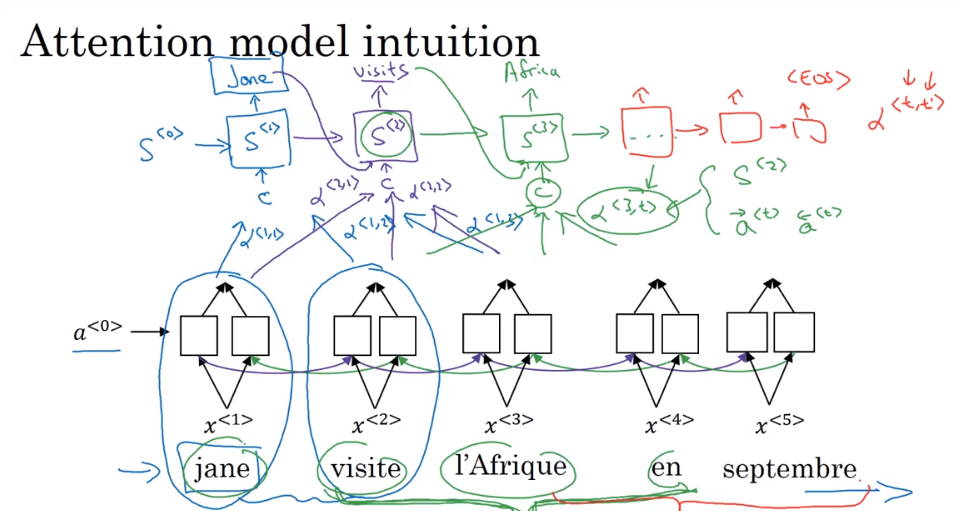
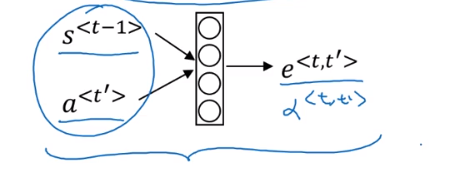
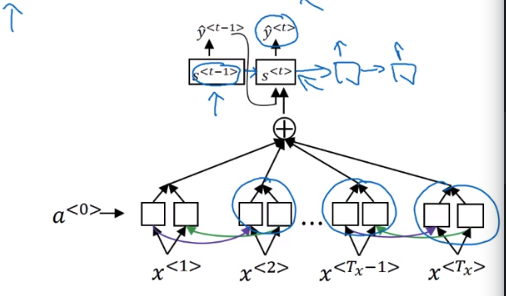
网络结构梳理
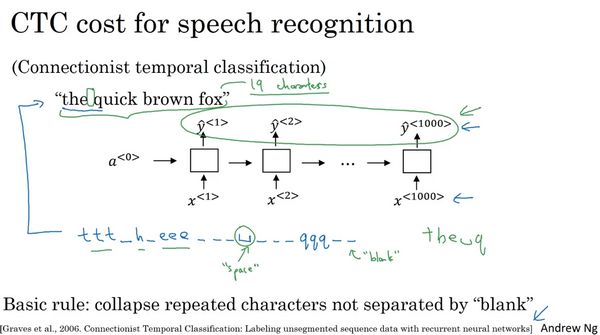
语音识别
- 输入音频
- 输出文字序列
phonemes方法
将声音分解为最基本的音位
CTC cost(Connectionist temporal classification)
- 折叠重复字符
触发字检测(Trigger Word Detection)
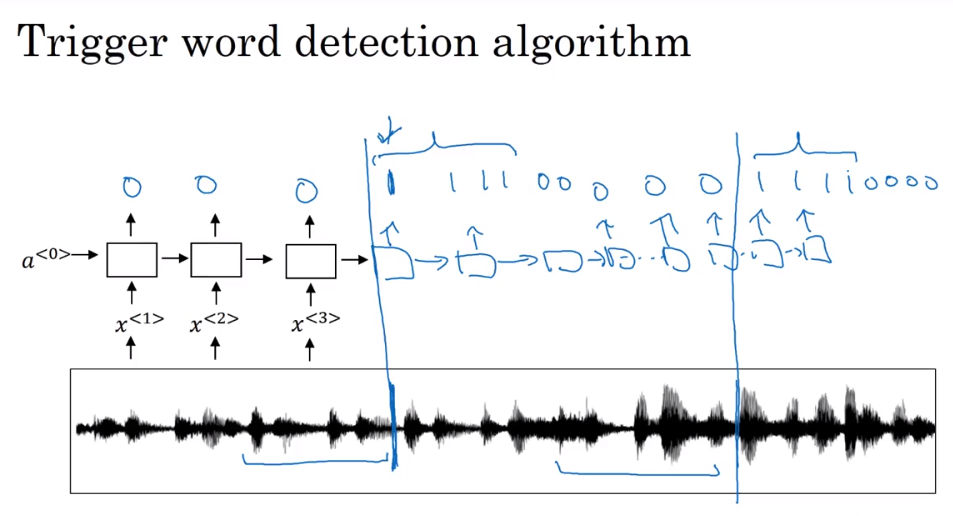
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 摸黑干活!
相关推荐

评论