信息熵
信息的基本分类
- 语法信息
- 语义信息
- 语用信息
符号系统
- X,Y:随机变量
- $x_k,y_j$ 变量取值
- $a_k,b_j$变量取值
- $\chi={x_k;k=1,2…K},\gamma={y_j;j=1,2…,J}$
- 事件:$X=x_k$
- $q_k=Pr{X=x_k}$
事件自信息
我们将特定事件$X=x_k$发生后给外界带来的信息量定义为事件的自信息
a=2的单位为比特
a=e的单位为奈特
事件自信息的本质既是事件对外界提供的信息,也是外界观察心信息付出的代价,通常认为概率越小的事件的信息量越大
条件自信息
事件Y=yj发生后X=xk发生给外界带来的信息
联合自信息
X=xk,Y=yj一起发生的信息量
事件互信息
互信息的本质为事件Y=yj
中包含的有关事件X=xk信息量,即可以是事件X发生的信息量减去事件Y发生后事件X还能给外界提供的信息量
互信息的对称性
互信息的性质
事件Y中包含X的信息量
条件互信息
联合互信息
联合互信息动链式法则
变量的平均自信息——熵
- 熵是随机变量不确定性的度量
- 熵是随机变量每次观察结果平均对外界所提供的信息量
- 熵是为了确证随机变量的取值外界平均所需要的与之相
关的信息量
条件熵
- 以事件 Y=y 为条件的变量X的熵
- 以变量 Y 为条件的变量X的熵
疑义度,在Y已知X剩余的不确定性
联合熵
联合链式法则
熵的性质

(5)可加性
对于变量X可以进行多步观察,每一步都可以从上一步观察的结果中得到更为细致的结果
(6)极值性
均匀分布时熵最大
凸性质

平均互信息
- 非负性
- 对称性
- 互信息与熵的关联性
求互信息常用上面的公式,相互独立的事件互信息为0
条件互信息
联合互信息
相对熵
一个变量的两种概率分布
表示实际分布p(x)和假定分布q(x)之间的平均差距,也称为鉴别熵
相对熵的性质
- 非负
- 非对称
- 与互信息关系
疑义度
错误概率
fano不等式
马尔可夫链
每个随机变量都是前一个随机变量一步处理的结果,任意一个节点已知,后面的变量和前面没得变量条件独立。
- 马尔可夫链是可逆的
数据处理定理
如果$X\to Y \to Z$
则$I(X;Y)>=I(X;Z),I(X;Y)>=I(X;Y|Z)$
四变量马尔科夫链
互信息的凸性
互信息I(X;Y)是关于输入分布{q(x)}和转移概率矩阵{p(y|x)}的函数
连续随机变量的互信息
基本性质
连续随机变量微分熵
连续随机变量的熵无穷大,所以引入微分熵的概念来衡量连续变量的相对不确定性
HC (X )不具有线性变换不变性,可正、可负
条件微分熵
联合微分熵
微分熵极大化
峰值受限
若 峰值受限于[-M,+M] 即 则 X为均匀分布微分熵最大
功率受限
若X的方差不大于$\sigma^2$,则X为高斯分布时微分熵最大
熵功率
- 定义连续随机变量 的熵功率为
- 高斯随机变量的微分熵
- 高斯变量熵功率
熵功率不等式
功率一定时,高斯变量的熵功率最大,与功率相等
平稳源
平稳源:任意长度的片段的联合概率分布与时间起点无关
简单无记忆源
平稳源的熵
平均每符号熵
熵速率
熵相对率
信源冗余度
平均条件熵
平稳源熵的性质
- 单调增
- $HN(X)>=H(X_N|X{N-1}…X_1)$
- $H{\infty}(X)=\lim{N\to\infty}HN(X)=\lim{N\to\infty}H(XN|X{N-1}…X_1)$
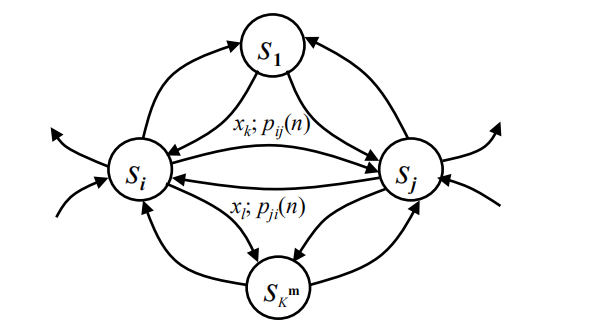
马尔科夫源
马尔科夫源的状态图
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 摸黑干活!

评论